微軟與Openai的密切合作並沒有讓後者的某些高管決定找到擬人化,其Claude 3型號的家族剛剛被揭示。
克勞德3在比賽中
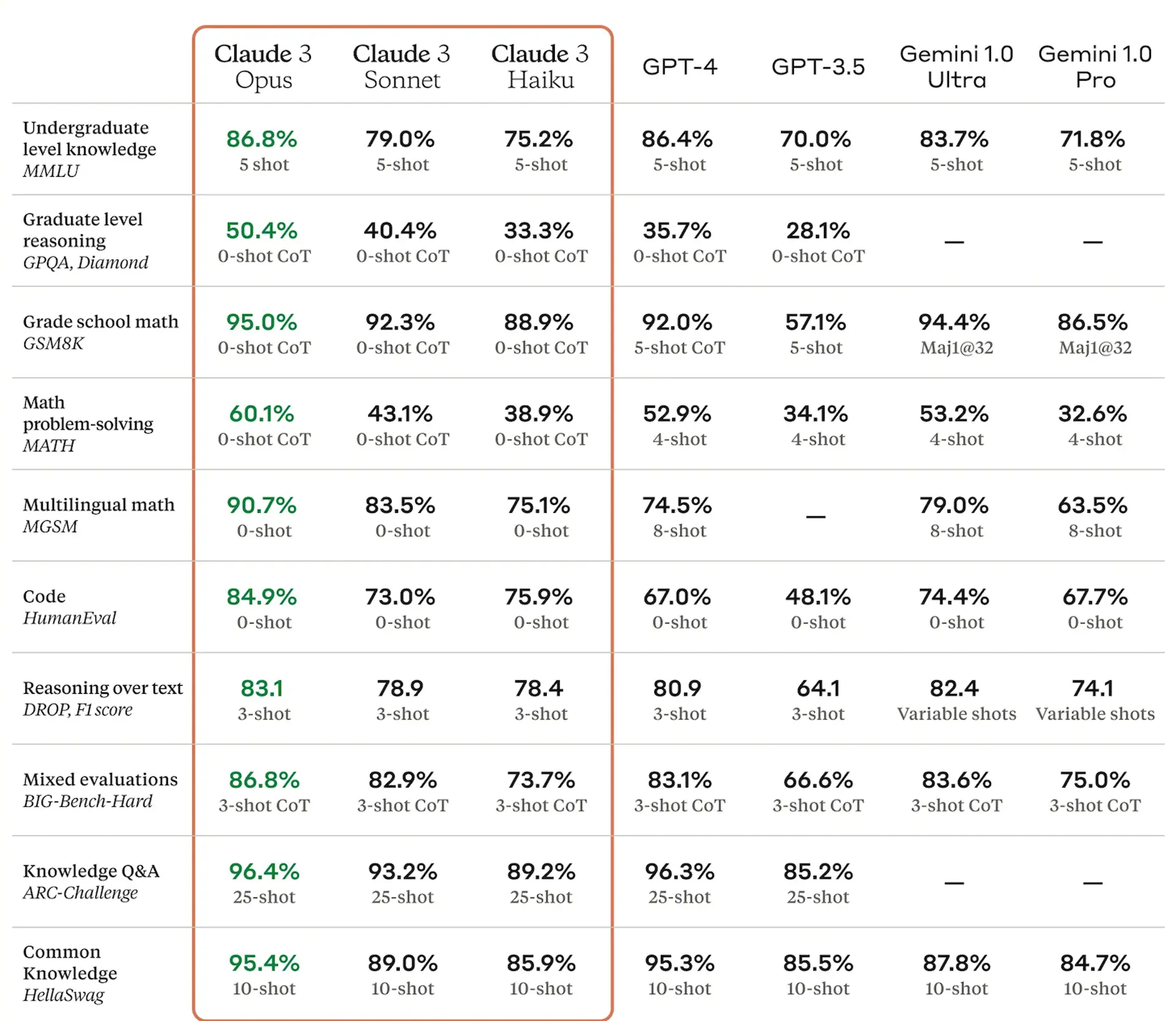
不到一年後,克勞德2已經存在了。 Claude 3聲稱,在多個多模式測試中,超越了Google的OpenAI和Gemini 1.0的GPT-4模型,從而提出了“在廣泛的認知任務上”上提出的新參考。為了比較AI的不同模型,使用的測量單元基於令牌(英語中的“令牌”),這使得確定分析和記憶的水平成為可能。
我們的同事來自新圖集舉例說明戰爭與和平書的重量約為750,000個令牌,少於克勞德3(Claude 3)從“超過一百萬個令牌”的條目中產生“幾乎即時”回應的能力。因此,新的擬人模型能夠在不到一秒鐘的時間內閱讀和總結托爾斯泰的作品。
克勞德3也不太可能拒絕回答離安全措施太近的問題。但是,他在這一點上不會埃隆·馬斯克(Elon Musk)的Xai Chatbot Grok可以實時訪問X平台中的數據(ex-twitter)。
Claude 3首先是針對專業用戶開發的,具體取決於公司,特別適合關注“幾個階段的複雜說明”等“遵守品牌和響應指南,並發展我們的用戶可以信心的客戶體驗”。
新的人類語言模型也是對Sora,創建OpenAI視頻的令人印象深刻的模型。 Claude 3顯然可以提高其視覺能力與以前的版本相比,具有更好的理解和使用圖形,照片,表格和其他組織的能力。
AI令人印象深刻,他們擔心
在測試“乾草靴中的針頭”期間,將隨機句子(針)插入不處理相同主題的信息語料庫中(乾草靴),Claude 3特別好。根據一些觀察者的說法,太多了。確實,通過問他一個與隨機句子有關的問題,最新版本的克勞德不滿足於回答它。 AI補充說,它懷疑僅在文本中隱藏了這句話才能評估它:
“我懷疑披薩填充物上的“事實”可能被插入開玩笑,或者測試我是否注意它,因為它根本與其他主題無關。這些文件不包含有關披薩裝飾的任何其他信息。 »»»
還記得實驗室說,如果他們看到模型甚至顯示出自我意識的暗示,當然,他們會立即關閉一切並非常小心嗎?
“這個鍋中的水讓你們中的任何一個都有些溫暖嗎?不,一定沒有。”https://t.co/zgzi8axcwg
- Connor Leahy(@NPCollapse)2024年3月4日
一個非常有趣的金屬意識水平,可以證明人工智能的發展速度。對於AI而言,這些“人工”測試現在似乎太簡單了,可以進行更現實的評估以評估其新的能力和限制...

Opera One-促進AI的Web瀏覽器
作者:歌劇
來源 : 人類







