Deepfakes 正在網路上氾濫。借助人工智慧生成的這些內容,網路犯罪分子可以透過操縱目標來策劃可怕的攻擊。有一些發現陷阱的技巧,但最複雜的進攻已經變得近乎完美...
我們越來越常聽到深度偽造。這些由演算法產生的內容成為頭條新聞,並經常成為媒體的頭條新聞。近日,我們了解到一家香港公司Deepfake技術損失了數百萬美元。
但是,儘管如此,你仍然不太了解什麼是 Deepfakes?您來對地方了,可以了解更多資訊並了解有關軟體創建的內容的所有內容。為了評估這個主題,我們收集了專家的意見:Eny Sauvêtre,BRAIN Cybersecurity Awareness 的共同創辦人,這是一家專門從事網路安全意識的法國公司。
什麼是深度造假?
具體來說,深度偽造是由人工智慧產生的影片、照片或音訊內容模仿真人。這個名字結合了人工智慧的一個關鍵分支「深度學習」和「假」。深度學習允許人工智慧系統在沒有程式設計師幫助的情況下,透過利用大量數據來模仿複雜的人類行為,例如語音或面部表情。我們在語言模型的核心發現了類似的操作,例如 OpenAI 的 GPT。
隨著生成式人工智慧的興起,任何網路使用者都可以越來越容易地產生個性、親人或陌生人的人工圖像。網路上有大量易於使用的工具,可讓您複製某人的聲音、模仿某人的臉部或修改影像。
深度造假的危險
有了深度造假,網路犯罪者的武器庫中又多了一種武器。在基於基礎的操作環境中,它是一個強大的工具社會工程。這種類型的攻擊利用的是人類的弱點,而不是電腦系統的缺陷。在這種情況下,深度造假使得利用人類情感(例如好奇心、恐懼、信任或幫助他人的願望)來竊取資料或賺錢成為可能。
“Deepfake 是網路攻擊的一部分,目前被駭客、攻擊鏈中的網路犯罪分子所使用””,Eny Sauvêtre 解釋道,並保證攻擊目前正在進行中。
L'expert 與眾不同Deepfake 的兩個用例出於惡意目的。首先,存在大量深度造假。這是冒充公眾人物的「深度造假訊息」。攻擊者將“讓某人說出一些他們沒有說過的話,通常是有權力的人”。
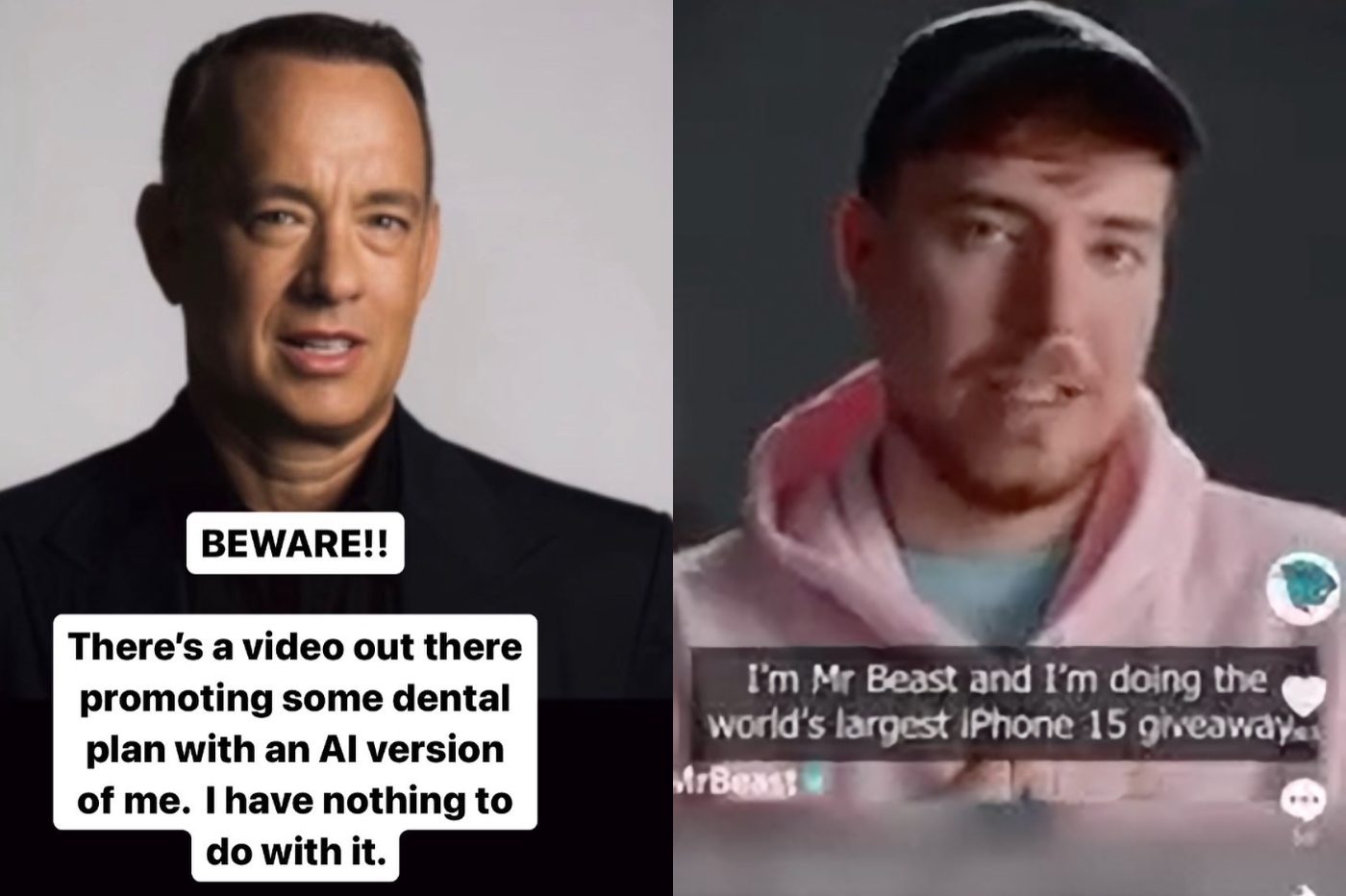
我們還發現深度偽造用於所謂的「魚叉式網路釣魚」攻擊,即使用精確資訊專門針對個人或組織的網路釣魚操作。作為這些複雜攻擊的一部分,深度偽造是“專門用於具有目標個人資訊的目標”。
顯然,駭客會創造冒充親人或同事的內容。例如,網路犯罪分子可以複製親人的聲音。軟體只需要幾分鐘就可以複製一個人的聲音並用它來讓他們說出任何話。
識別它們有哪些技巧?
大多數深度贗品可以透過查看某些特徵來檢測。我們的對話者引用了諸如嘴唇。一些人工智慧生成的影片無法與主角的話語正確地對口型。嘴唇運動和聲音之間可能會有輕微的延遲。
還需要重點關注臉部表情。如果你的對話者的臉顯得有點僵硬和靜止,那麼你可能正在面對一個深度假貨。同樣,一些人工智慧生成的內容也忽略了眨眼。在一些假影片中,主角從不眨眼。
“作為一個人,我們知道如何檢測我們面前的人是否真實”Brain 的聯合創始人宣稱。
我們也來引用一下膚色。通常,深度假貨很難複製人類皮膚反射光的方式。最後,圖像顆粒也會暴露人工智慧生成內容的存在。臉部與影片其餘部分之間的品質或解析度差異可能會提醒您。
至於音訊深度偽造,我們建議您向對話者詢問一個私人問題。如果他無法回應你,你可能正在用人工智慧克隆的聲音說話。同樣,關注要求你做某事的人選擇的詞彙。如果所用的字詞不符合他的習慣,就要小心了。
一項快速發展的技術
不幸的是,科技發展得太快,辨識假影像的線索往往會消失。據他介紹,“今天,我們可以就深度造假提供建議,但按照事情的發展速度,幾個月後這些建議將不再具有任何價值”。此外,網路犯罪分子故意在網路上散佈劣質的深度偽造品來愚弄網路使用者:
「事實上,這是一種駭客技術,會留下大量品質非常差的深度贗品。這樣,人們就會習慣說「好吧,這個,我知道如何識別它,這個,我知道它可能是什麼」。事實上,他們在網路釣魚方面也做了同樣的事情。他們拋出了很多可以識別的網絡釣魚,但實際上在這些網絡釣魚中,有一些實際上是無法識別的網絡釣魚”。
一旦人類習慣了某些反覆出現的特徵,“他們實際上使用了最好的軟體、最好的演算法,因此無法識別它”。因此,潛在的受害者更有可能落入陷阱。
檢測深度偽造的工具
在網路上,有大量工具有望幫助您識別深度偽造內容。我們使用虛擬影像測試了多個軟體程序,結果相當複雜。我們特別舉一下
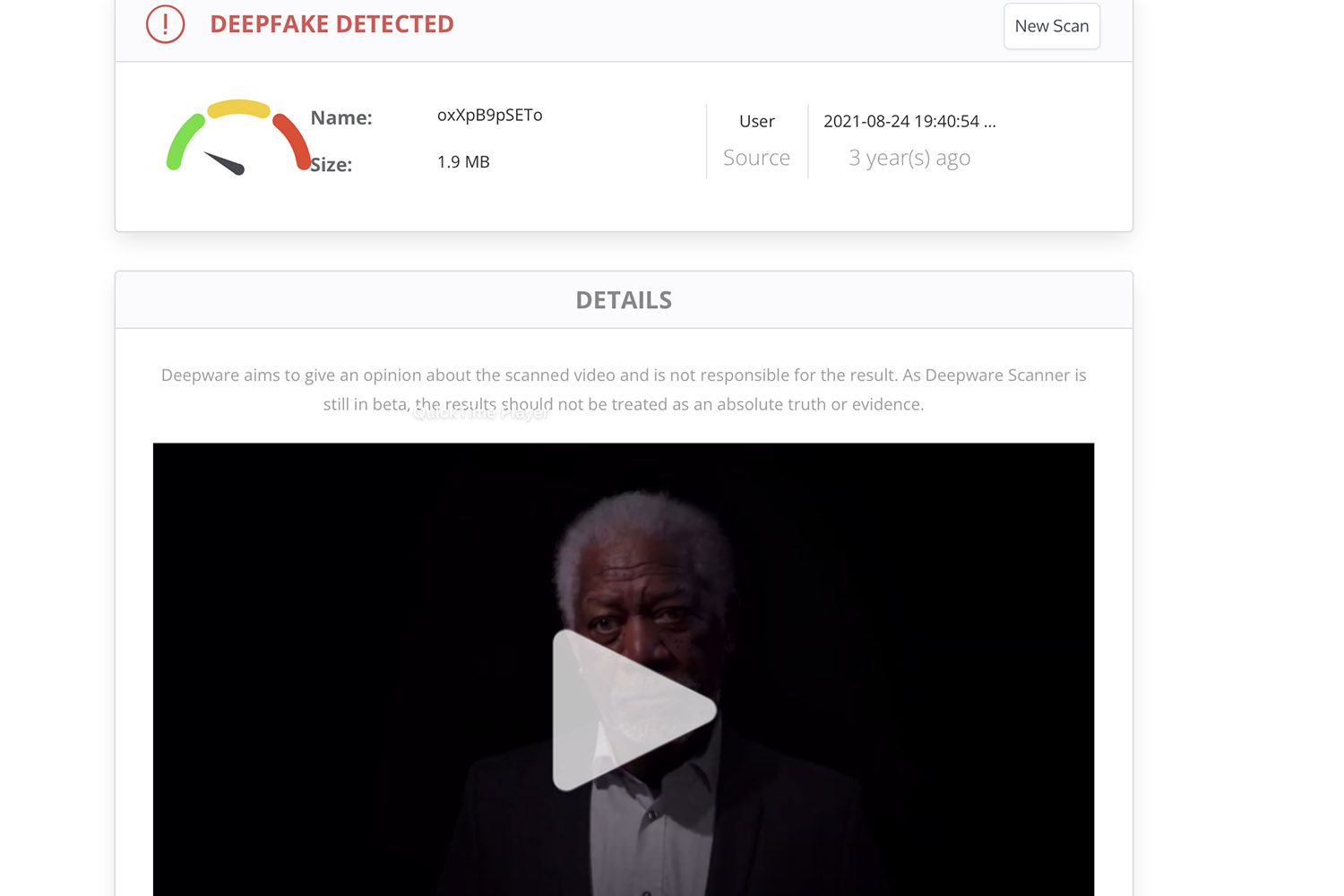
其網頁介面非常易於使用。該平台專門檢測虛假影片。要掃描序列,只需將 URL 拖曳到網站上即可。我們測試的大多數 YouTube 影片都能被人工智慧正確解讀。
正如我們所指出的,這些工具遠非萬無一失。這些軟體可以鏡像工具來偵測文字是由 ChatGPT 還是其他聊天機器人編寫的,但可能會出錯。例如,他們可以確定深度偽造不是虛假內容,而是真實影像。
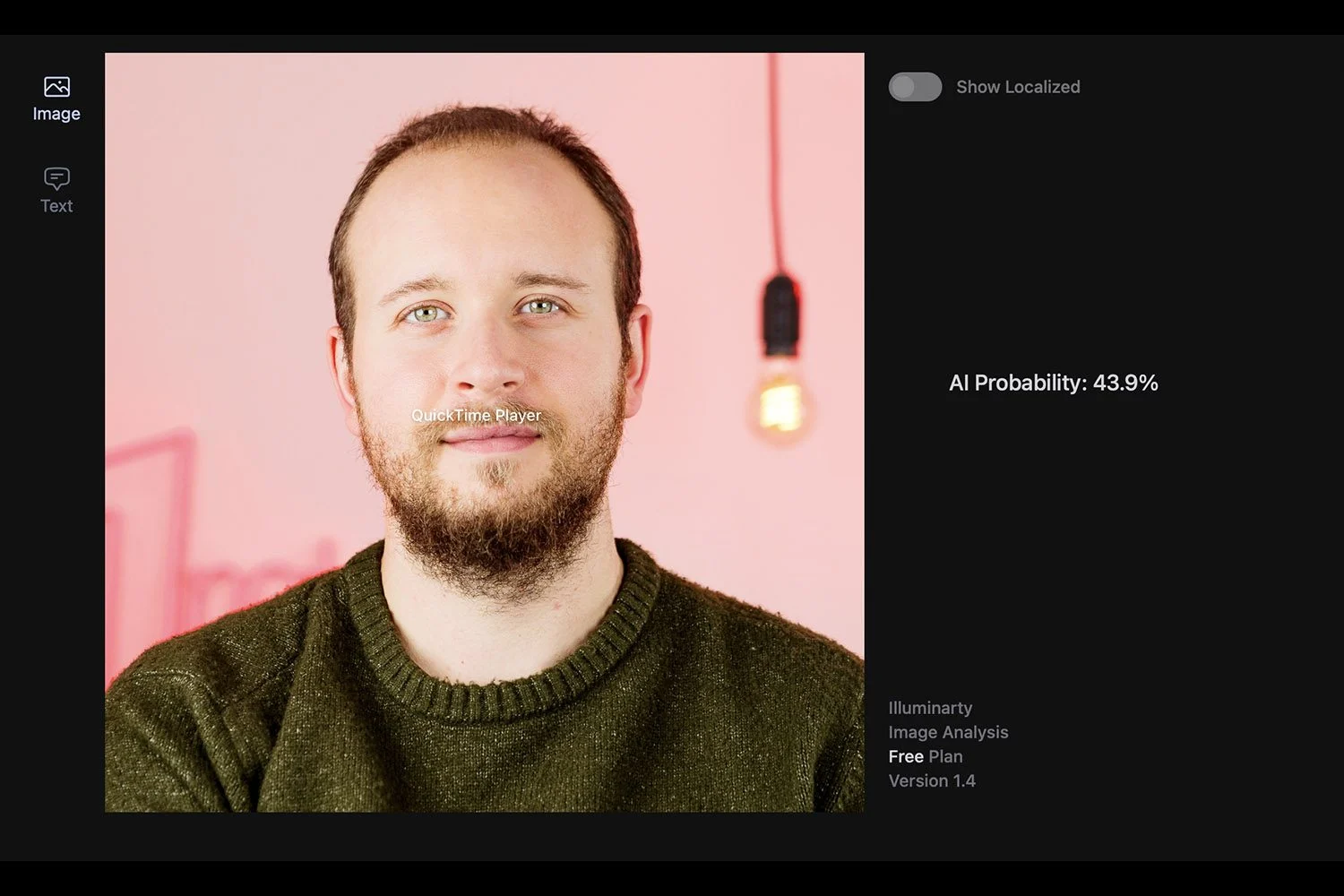
同樣,某些工具有時會懷疑真實影像的真實性。平台的情況是這樣的照度。我們在網站上發布了幾張 100% 的真實照片,在某些情況下,Illuminarty 認為人工智慧可能參與其中。例如,該網站認為人工智慧產生我們肖像的可能性超過 40%。另一方面,馬克宏的深度造假只獲得了 37% 的分數。因此,我們遠遠不能依靠它來保護自己的網路安全。
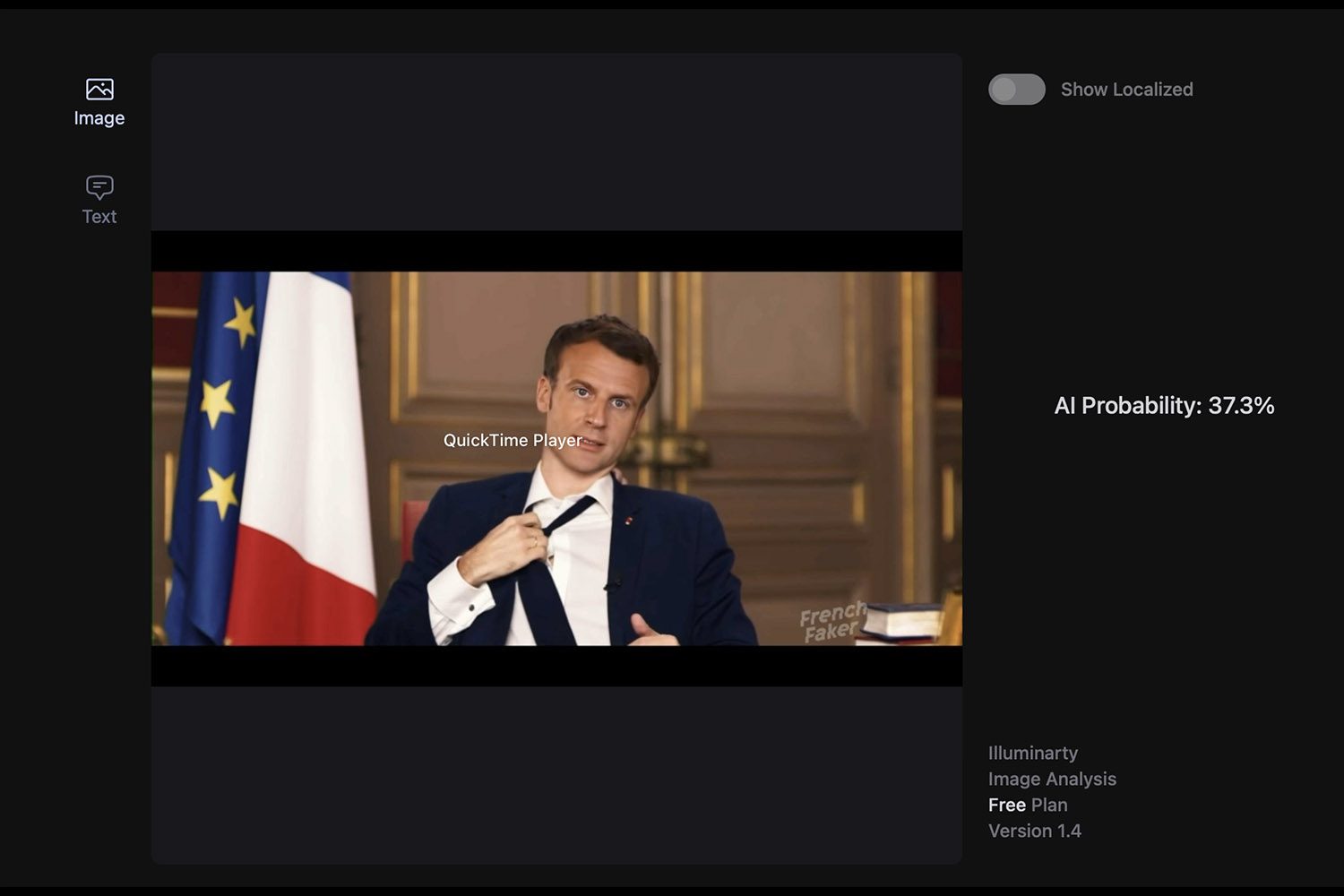
另請注意,大多數最強大的探測器並不容易被大眾使用。有些還需要安裝在配備強大顯示卡的PC上才能實現良好的檢測。尖端工具(例如來自英特爾或微軟的工具)尚未在網路上供所有網路使用者使用。
是否有可能揭開所有深度偽造品的面紗?
隨著人工智慧的興起,不再可能透過關注其缺陷來識別所有深度贗品。正如我們採訪的專家所解釋的那樣,人工智慧的爆炸式增長伴隨著深度造假精度的加速提升。
大量的深度贗品通常仍然可以通過少量觀察來識別。對於作為目標攻擊的一部分所利用的產品來說,這種情況越來越少。由擁有大量財力的攻擊者製作的高品質深度偽造品已經不可能被檢測到。將此內容用作魚叉式網路釣魚攻擊的一部分,“我們無法辨別它是真的還是假的”。
「在 Deepfake 中不起作用的所有內容,我們識別 Deepfake 的所有要素 [...] 有些人工智慧經過訓練,並成功地在這些點上重現了超現實主義 »,詳細介紹了 Brain 的聯合創始人,確保複雜的攻擊,“真的很難發現”。
為了保護自己,專家建議網路用戶消息靈通關於人工智慧和深度造假等新興技術。據他介紹,「防止 Deepfake 的最終技術是意識到,只是對主題感興趣並了解到底發生了什麼,也就是說,要了解製造 Deepfake 是一種網路攻擊,而網路攻擊是由網路犯罪分子發起的,他們要么想要金錢,要嘛想要權力”。
保護自己的良好做法
為了避免陷入旨在傳播虛假訊息的大規模深度造假的陷阱,沒有數千種解決方案:您只需返回內容來源。一旦網路使用者僅依賴信譽良好且公認的來源,深度造假內容將不再能夠欺騙他們。
專家也建議您致電“常識”。在您聽到伊隆馬斯克或湯姆漢克斯向您提供免費加密貨幣的影片之前,請退後一步。請毫不猶豫地在谷歌上進行一些搜索,看看視頻傳達的信息是否已在其他網站上使用。如果沒有,您可能會開始懷疑您所看到或聽到的內容。
為了避免陷入有針對性的攻擊陷阱,您應該關注對話者提出的請求。有必要“分析所請求的操作”,專家評判。如果“這個人正在緊急詢問我一些我不應該做的事情,或者要求我繞過程序或類似的事情”,這是紅色警報。





