在過去的幾年中,Deepfake視頻一直存在,有些人通過使用不同的演員來操縱電影和電視場景在其中找到了一些樂趣,但是通過人工智能操縱現實生活的鏡頭也可能非常危險,因此Deepfake探測器在事實檢驗和拍攝醫護視頻方面非常有用。
但是,據加州大學聖地亞哥分校的計算機科學家稱,事實證明,這種工具可以被擊敗。
使用“對抗示例”
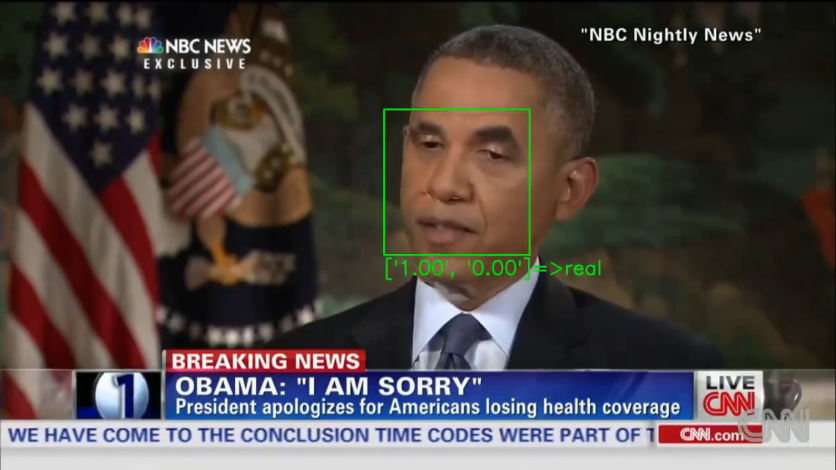
在一份報告中新聞18,可以通過添加稱為“對抗性示例”的輸入來使DeepFake探測器被愚弄,這些輸入略微操縱輸入。
對抗性的例子導致人工系統(如機器學習模型)犯錯誤,認為深深的視頻從未被觸摸過,並且根據加州大學聖地亞哥分校的科學家的說法,儘管壓縮了虛假視頻,但該攻擊仍然可以奏效,這應該能夠刪除虛假功能。
基本上,探測器可以通過專注於面部特徵(例如眼動動作)來確定偽造的視頻,這些視頻通常在操縱視頻中繁殖不佳。
不幸的是,這種方法甚至可以欺騙最複雜的檢測器。
令人震驚的證據是在2021年1月5日至1月9日舉行的有關計算機視覺應用(WACV)2021的應用的上一場冬季會議上展出的。
“可能是現實世界的威脅”
計算機工程博士學位Shehzeen Hussain說:“我們的工作表明,對DeepFake探測器的攻擊可能是現實世界中的威脅。”加州大學聖地亞哥分校的學生,以及UCSD Jacobs工程學院的WACV紙的第一任學生在線報紙。
侯賽因進一步說:“更令人震驚的是,我們證明,即使對手可能不了解探測器使用的機器學習模型的內部運作,也可以在強大的對抗性深層製作。”
根據該報告,即使在註入對抗性例子時,科學家也能夠打敗甚至最複雜的探測器的警惕。
高成功率
為了測試攻擊,研究人員創建了兩種情況:一種可以完全訪問檢測器模型的情況,包括分類模型的體系結構和參數以及面部提取管道;還有另一個只能查詢機器的地方。
在第一種情況下,科學家在未壓縮視頻中取得了99%的成功率,壓縮錄像帶的成功率為84.96%。
在第二種情況下,未壓縮視頻的成功率為86.43%,壓縮文件為78.33%。
科學家說,這是第一次證明探測器可以被擊敗的證據。
因此,本文背後的科學家正在鼓勵對軟件進行改進的培訓,以更好地檢測此類操作,建議一種與他們所謂的對抗性訓練相似的方法,其中自適應對手不斷產生新的深擊,而探測器則繼續學習檢測操縱樣品。
他們還拒絕釋放使用的代碼,以免被敵對政黨使用。
本文由技術時報擁有
撰寫者:NHX Tingson