通过将浮点计算标准形式化为 8 位而不是 16 位甚至 32 位,ARM、英特尔和 AMD 三巨头将加速人工智能训练。由于计算和内存需求的减少,该频段降低了这些操作的财务和经济足迹。
训练人工智能需要越来越多的时间,并且在机器时间和能源足迹方面的成本也越来越高。为了解决这个问题,ARM、Intel 和 Nvidia 等巨头已就 8 位浮点计算标准 FP8 达成一致。在一份联合出版物中,这三个公司甚至免费提供了 FP8 标准。这远非纯粹的慈善事业,而是相当合乎逻辑的:他们(直接或间接)出售芯片来进行这些计算。
对于那些通过 AI 计算中的位数(NES 为 8 位,SuperNes 为 16 等)来衡量游戏机性能的人来说,增加精度并不一定是万能的,这或许与直觉相反。根据这三个公司的研究人员的说法,FP8 的计算结果是“快乐的媒介» 结果的质量和所需的计算能力之间的关系。 Nvidia 官员解释说 FP8 提供“可比精度» 计算机视觉任务或图像生成系统(如 Dall-E)中的 16 位计算。同时允许加速“重要的» 这些计算。
与图像相关的任务相比,更青睐 FP8 计算并非凭空而来,这一点已在业界达成共识。例如,高通公司已经倾向于在其性能测量测试中运行 FP8。还认为这种精确度是“充足的»。
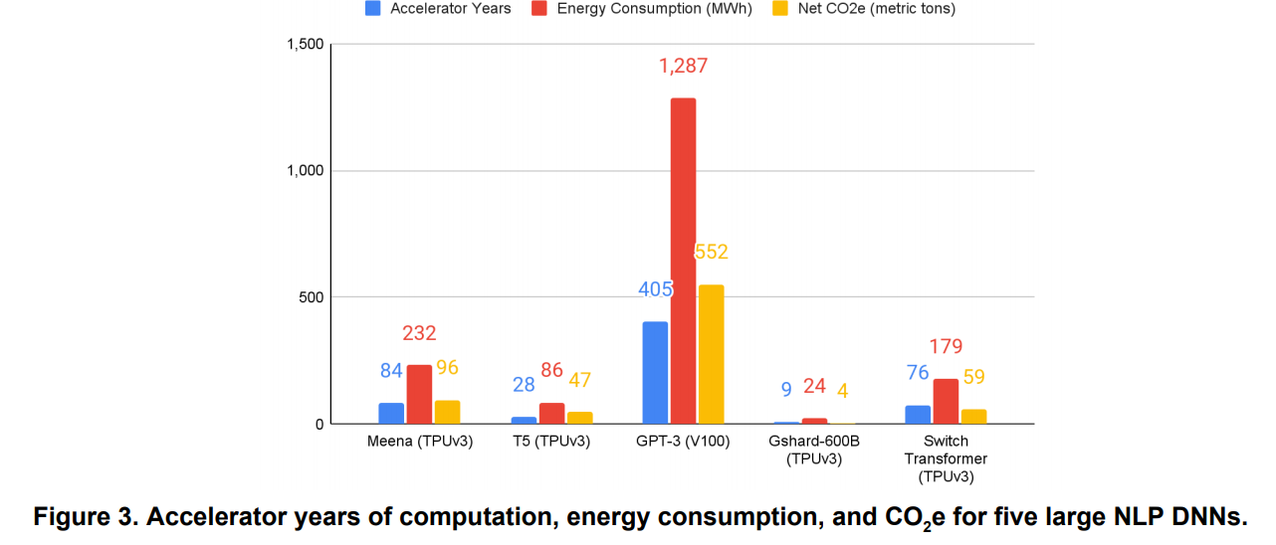
从技术层面来说,降低计算精度意味着加快任务执行速度。这种加速通过反弹提供了另一个优势:限制处理器(CPU、GPU、AI)的使用时间/数量。然而,GPT-3等训练模型的改进和复杂性推高了财务和能源费用。工程师和研究人员有时花费数十万甚至数百万欧元或美元来训练人工智能。我们每天受益的培训:相机的场景或主题识别等。
如果 FP8 标准化有效,也不要完全高兴。这将限制“损害”并允许软件和硬件(日益优化和高效的芯片)取得重大进展。但这也将降低入门价格,并鼓励此类计算在更多行业中推广。
来源 : Techcrunch.com







