正如预期的那样,NVIDIA作为从AI崛起中受益最大的公司之一,受益于GTC(GPU技术大会),将于本周在加利福尼亚州圣何塞举行,展示其新的 GPU;还没有GeForce RTX 50 系列,而是Blackwell GPU 适用于数据中心,该公司已经预计其需求非常强劲。其首席执行官黄仁勋由此推出了H100、H200和GH200的后继产品:与前两者一致的B100和B200,以及继承了后者的GB200。
布莱克威尔,我没有通过 au MCM
人们已经期待了几个月,现在已经正式宣布:Blackwell 架构标志着 MCM 设计的采用(多芯片模块)。 AMD 已使用它,它比旧的单片设计具有更大的灵活性。 Blackwell 受益于台积电的 4NP (4nm) 工艺。

明星当然是 B200。它响应了 Jensen Huang 提出的需求,“拥有更大的 GPU”以满足生成式人工智能的需求。舞台上,穿皮夹克的人直接将Hopper芯片与Blackwell GPU进行了比较;事实上,存在尺寸差异。然而,Hopper 辩称,B200 并不是传统意义上的单一 GPU。它由两块芯片组成,作为统一的 CUDA GPU。它们通过 NV-HBI 连接(NVIDIA 高带宽接口) de 10 To/s。

在不列出数值的情况下,B200 拥有 2080 亿个晶体管,而 H100 / H200 则为 800 亿个。该芯片配备 192 GB HBM3e 内存,带宽为 8 TB/s,AI 性能比其型号高出五倍。更具体地说,Blackwell 的每个芯片在 FP8 中的训练性能是其前身的 2.5 倍,在 FP4 中的推理性能是其前身的 5 倍。但请注意,FP4 精度特定于新的 Blackwell 架构(还添加了新的 FP6 格式)。因此,我们必须依靠 FP8 来比较 Blackwell 和 Hopper。此外,功耗也会增加,每个芯片的功耗约为 1000 W,而 Hopper GPU 的功耗为 700 W。

此外,第五代 NVLink 互连速度是 Hopper 的两倍,支持多达 576 个 GPU。
B100无权获得如此完整的展示。正如其数字所示,它的功能预计会比其型号稍弱一些。 NVIDIA 只是在某些产品中提到了这一点,例如下面提到的 HGX B100。我们来自 AnandTech 的同事表示,这是一个拥有 1040 亿个晶体管的单芯片,但这一说法需要得到证实。
B200 有各种口味可供选择
回到B200,它也将用于GB200 Grace Blackwell。它是 GH200 Grace Hopper Superchip 的后代。我们找到了一对与 NVIDIA Grace CPU(72 个 Arm Neoverse V2 内核)相关的 B200。该套件拥有高达 384 GB 的 HBM3e。 TDP 为 2700W。

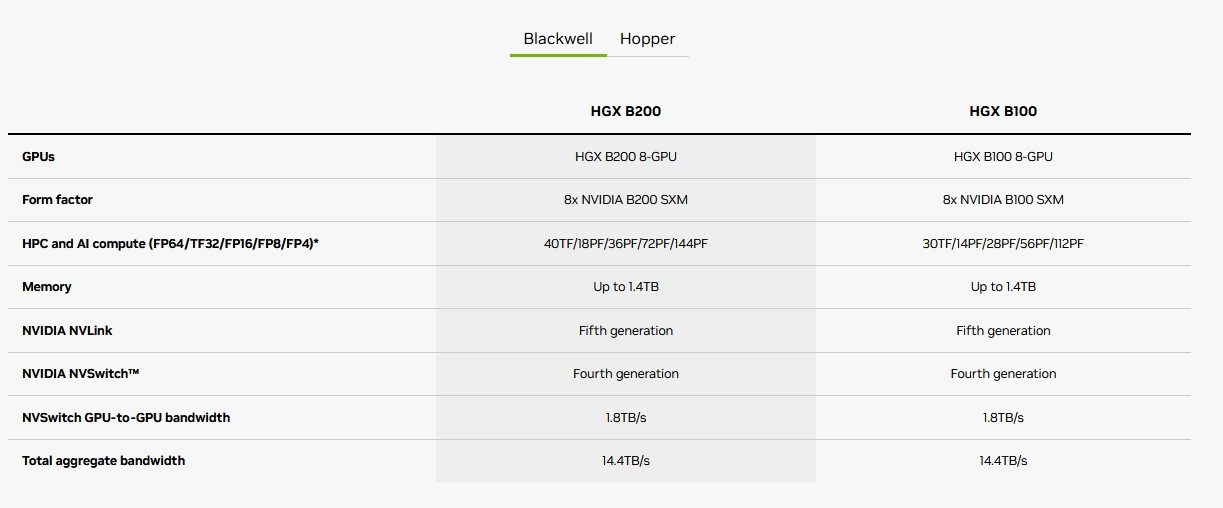
为了完整起见,我们还要提一下 DGX B200 站,它配备 8 个 B200 GPU 和两个 Intel Xeon Platinum 8570 处理器;并且,谈谈配备 8 个 SXM 格式 B200 / B100 GPU 的 B100、HGX B200 和 HGX B100(服务器 PCI Express 模块)。
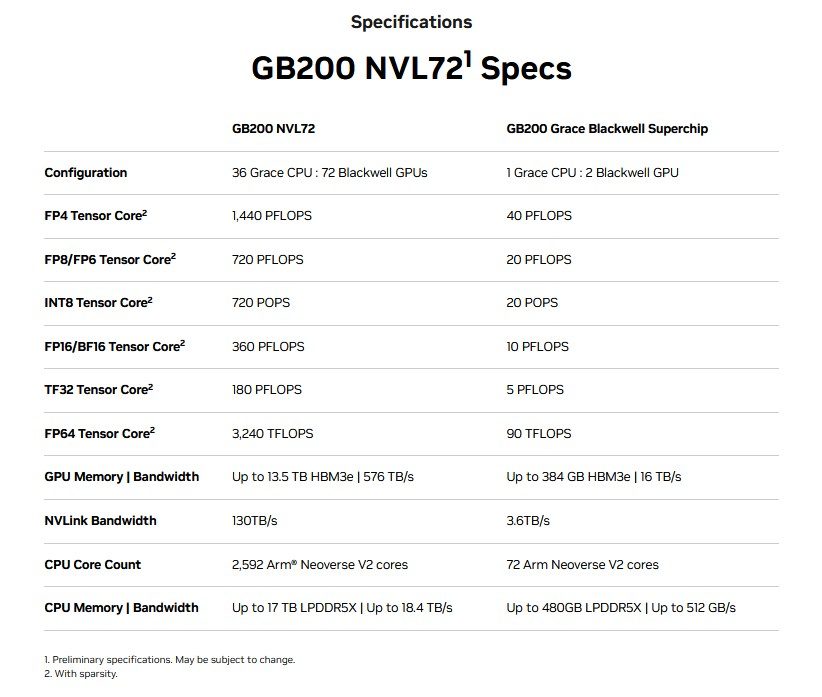
最后,与负责管理 NVLink 互连的称为 NVLink Switch 的其他芯片相结合,GB200 成为 GB200 NVL72(多节点、液冷、机架规模系统)的构建块。菜单上有:36 个 Grace CPU 和 72 个 Blackwell GPU,可实现 720 petaflops 的 AI 训练性能和 1.4 exaflops 的 AI 推理性能。

对于GB200 NVL72,黄仁勋表示:“就在我们说话的时候,地球上只有几台百亿亿级机器,也许三台。这是单机架中的百亿亿次人工智能系统”。
让我们以一点文化笔记结束。 NVIDIA 架构的名称是为了向加州大学伯克利分校专门研究博弈论和统计学的数学家 David Harold Blackwell 致敬,他也是第一位入选 NVIDIA 的黑人研究员。美国国家科学院。
来源 : 英伟达





