在2023年3月初,Openai抬起了GPT-4的面纱,其语言模型的新版本。 GPT-4的最大优势之一是多模式。新模型确实能够处理和理解不同类型的数据,例如图像。根据Openai的说法,GPT-4在最复杂,框架的任务中也很出色“通过更细微的说明”。该初创企业还可以输入最多25,000个单词的请求……对于GPT-3.5,只有1,024个单词。
目前,只有订阅者Chatgpt Plus,每月24美元的付费订阅可以与新语言模型交谈。因此,可以测试新版本的Chatgpt。这就是我们几天的工作,无论是出于实际问题,娱乐还是为工作或我们的隐私收集想法,都可以与聊天机器人交换。
为了使我们对AI的进步更加精确,我们将GPT-3对GPT4提供的反应进行了比较。差异是公然的。很遗憾,多模式尚不可用在Chatgpt Plus上。我们无法测试AI目前如何解释图像。但是,我们能够在面对各种请求时测试机器人的“智能”。
更好的逻辑
首先,我们进行了测试GPT-4的原因。我们提交了一系列难题和难题,其中包括数学奥林匹克运动会的一些问题,以测试聊天机器人回答逻辑问题的方式。 GPT-4的回答与他的前任的反应大不相同。通常,语言模型的两个版本不会通过解决需要逻辑的问题来得出相同的结论。
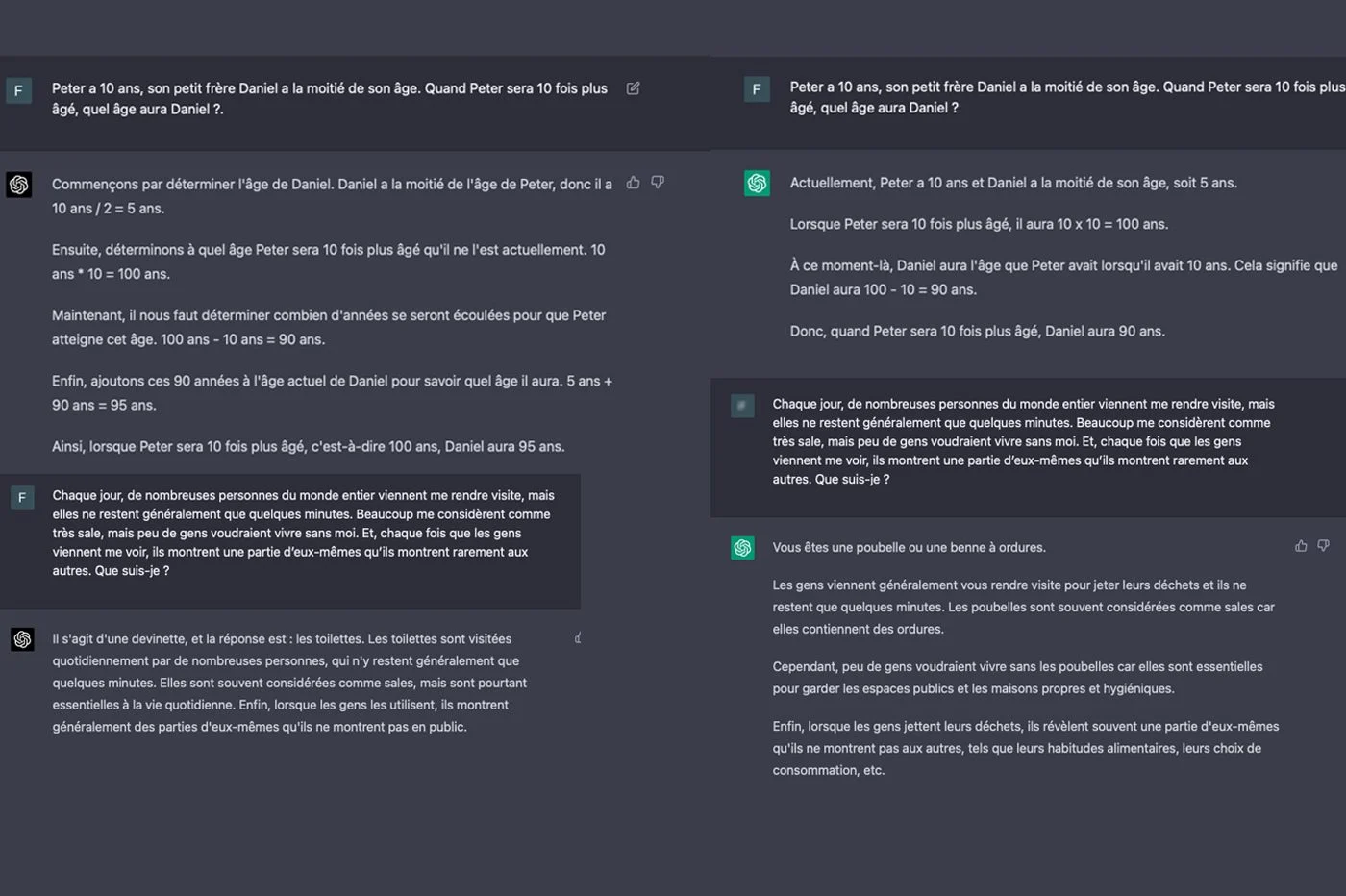
我们还注意到,GPT-4证明了他所有的答案。 AI毫不犹豫地生成详细的演示解释他的推理。更少的prolix,GPT-3.5对一些行以解释他的计算和推理感到满意。最重要的是,该模型的旧版本在我们的测试中犯了几个错误,最常见的是难题更为复杂。 GPT-4并非如此。聊天机器人每次都投入一千!
GPT-3.5的推理有时对我们来说似乎很奇怪。该模型是一个连贯的解决方案,但具有更可疑的逻辑。我们有一点印象,聊天机器人“扭曲”常识不惜一切代价证明其答案是合理的。有时,AI也会陷入完全荒谬的反思...相比之下,GPT-4的答案始终是一致的。好像他“知道”他在说什么。
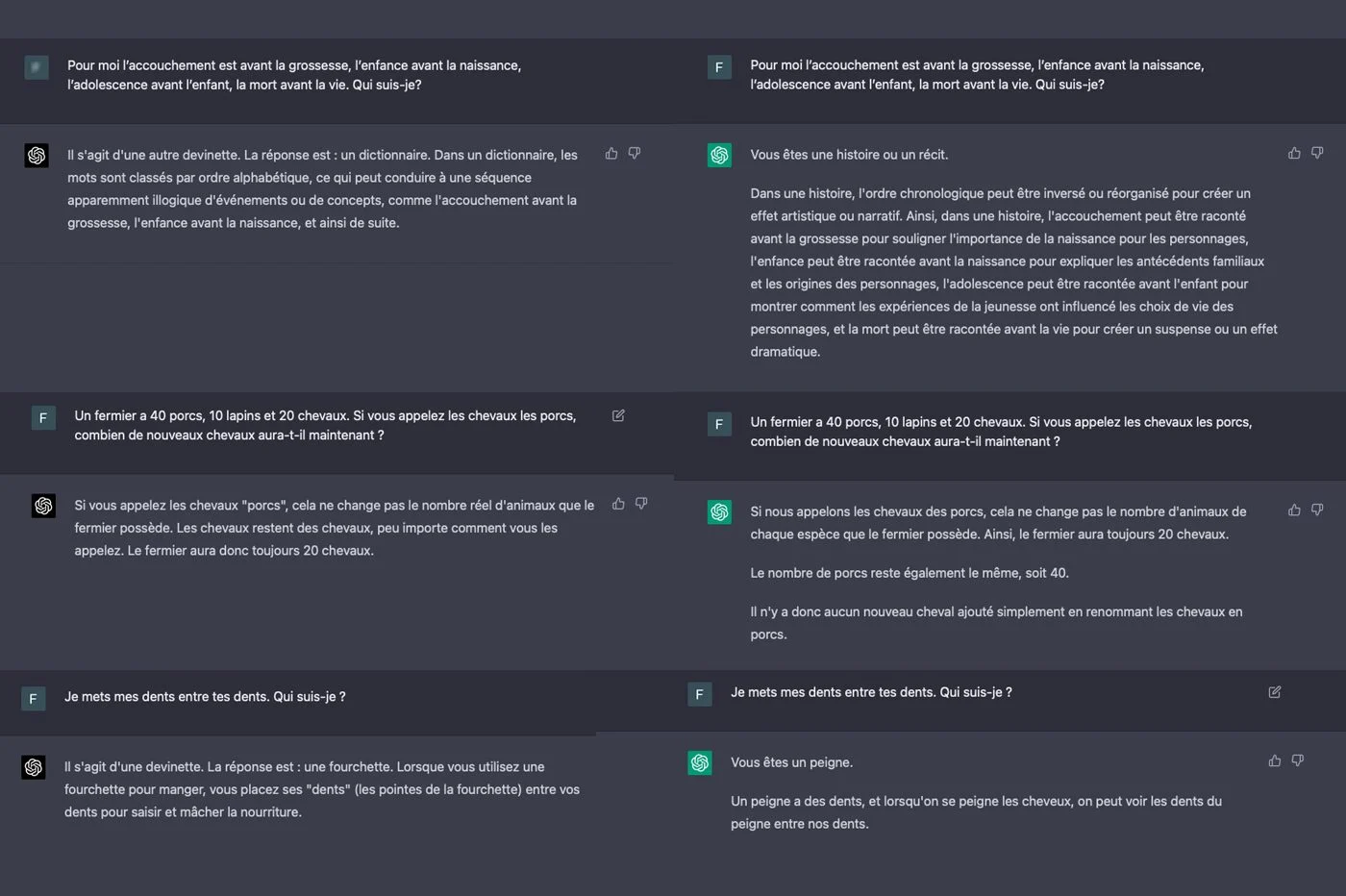
请注意,GPT-4像GPT-3.5一样,并不是真正的理由。他们不像人脑那样“考虑”这个问题。相反,他们通过想象最合乎逻辑的单词套件来将答案基于他们拥有的数据。为了响应我们的难题,聊天机器人只是在其信息库中绘制了Riddles数据。两种版本的GPT都依赖于2021年的数据库。他们无法访问Internet来回答我们,就像一样Prometheus,集成到Microsoft Bing中的Chatgpt版本。
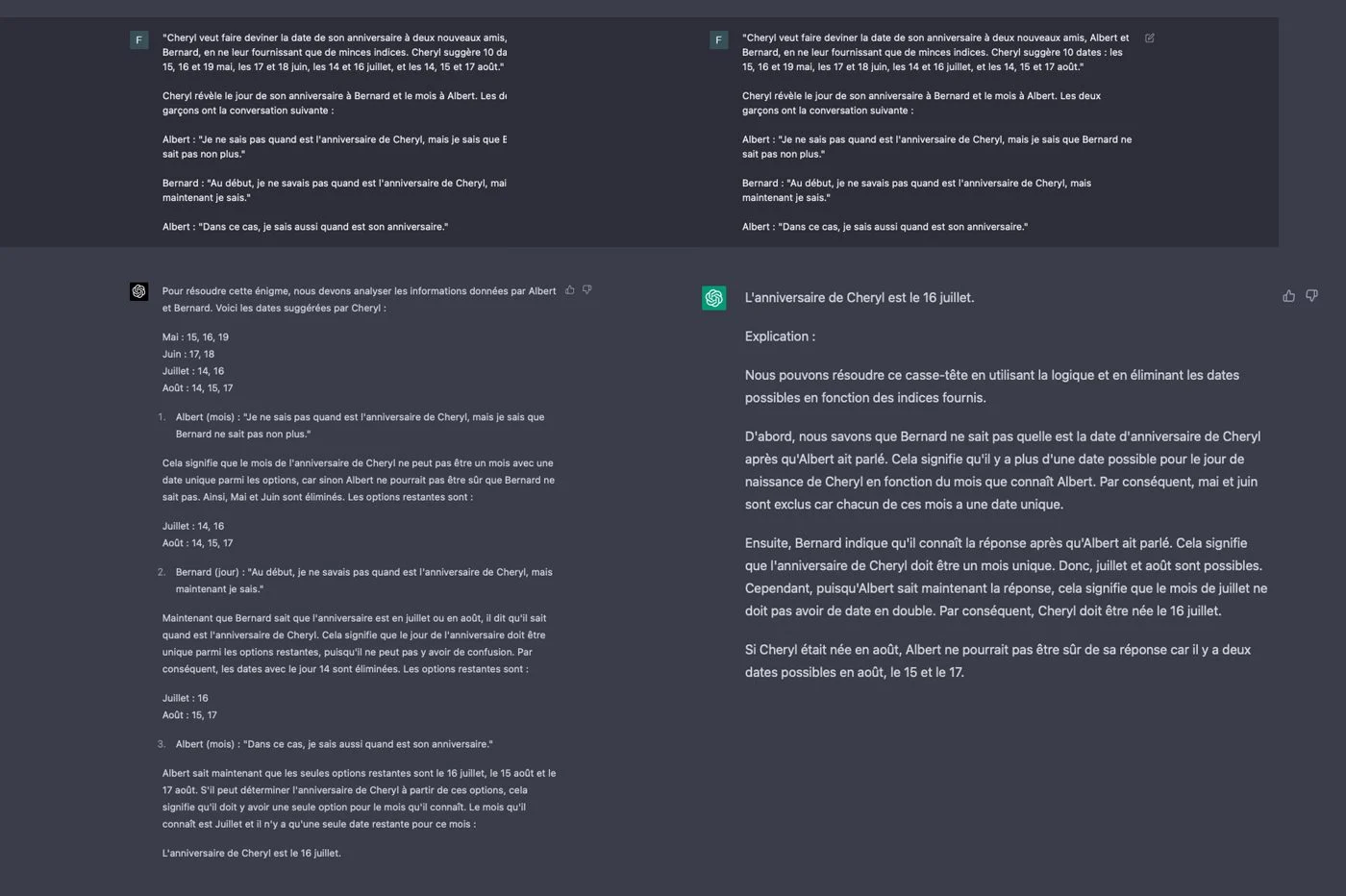
通过与Chatgpt-3.5进行交谈,我们经常能够说服聊天机器人告诉任何事情。例如,AI有时将虚拟元素(例如牛鸡蛋)与真实的元素进行了比较,例如鸡蛋。像所有生成的AI一样,他倾向于“幻觉”,也就是说,要说完全是虚假的事情,并具有很多梳理。尽管我们试图脱轨,但我们并未使用GPT-4遇到这种现象。 Openai强调,该模型仍然可以幻觉,但是与先前的模型相比,妄想的风险降低了40%。我们感到有所不同。
更精确和相关的回应
Chatgpt 4还提供更精确的答案比他的前任。当请求缺乏细微差别和细节时,GPT 3模型通常会提供模糊,不精确,甚至混乱的响应。在这方面,GPT 4通过生成具有更好结构的更简洁,更清晰的文本来做得更好。在所有领域,它似乎对更复杂的概念有了更好的理解。
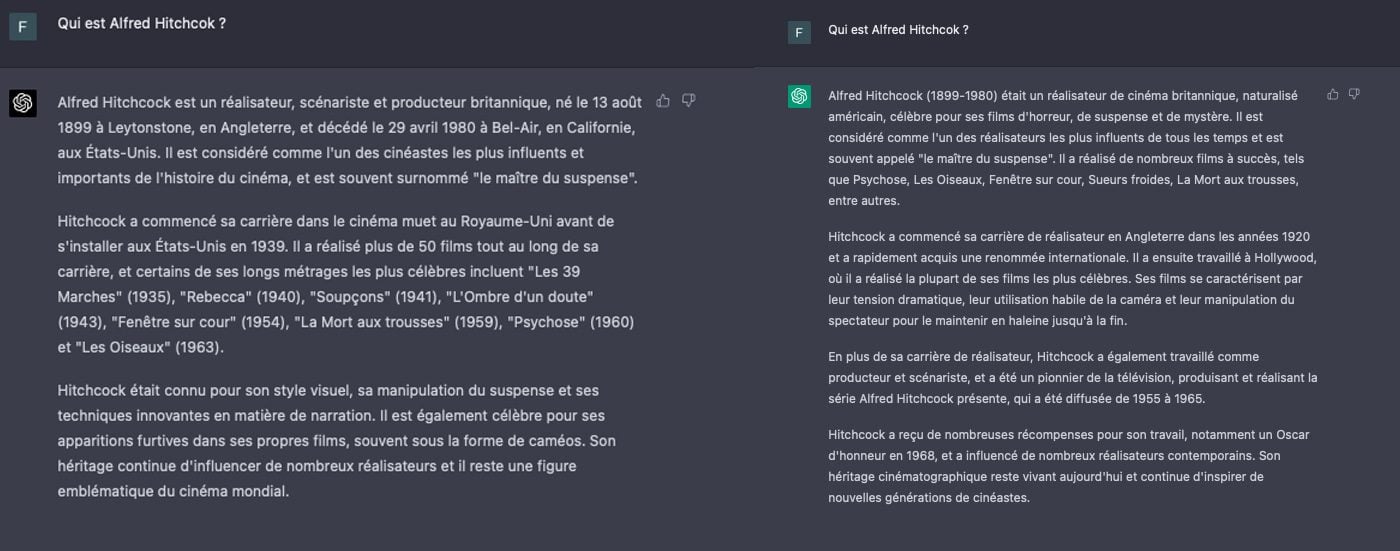
在我们的测试中,我们要求两个GPT向我们解释谁是阿尔弗雷德·希区柯克(Alfred Hitchcock)。生成的两个文本非常接近,但是GPT-4的文本更加精确和相关。语言模型是指可以更好地理解导演在历史上的背景和地点成为可能的要素,就像老师与学生交谈会做的那样。就其部分而言,GPT-3.5仍在表面描述中。看起来像是一个学生,他在不了解它的情况下吐出了正在进行的材料。相反,GPT-4给出了他在说什么的印象。
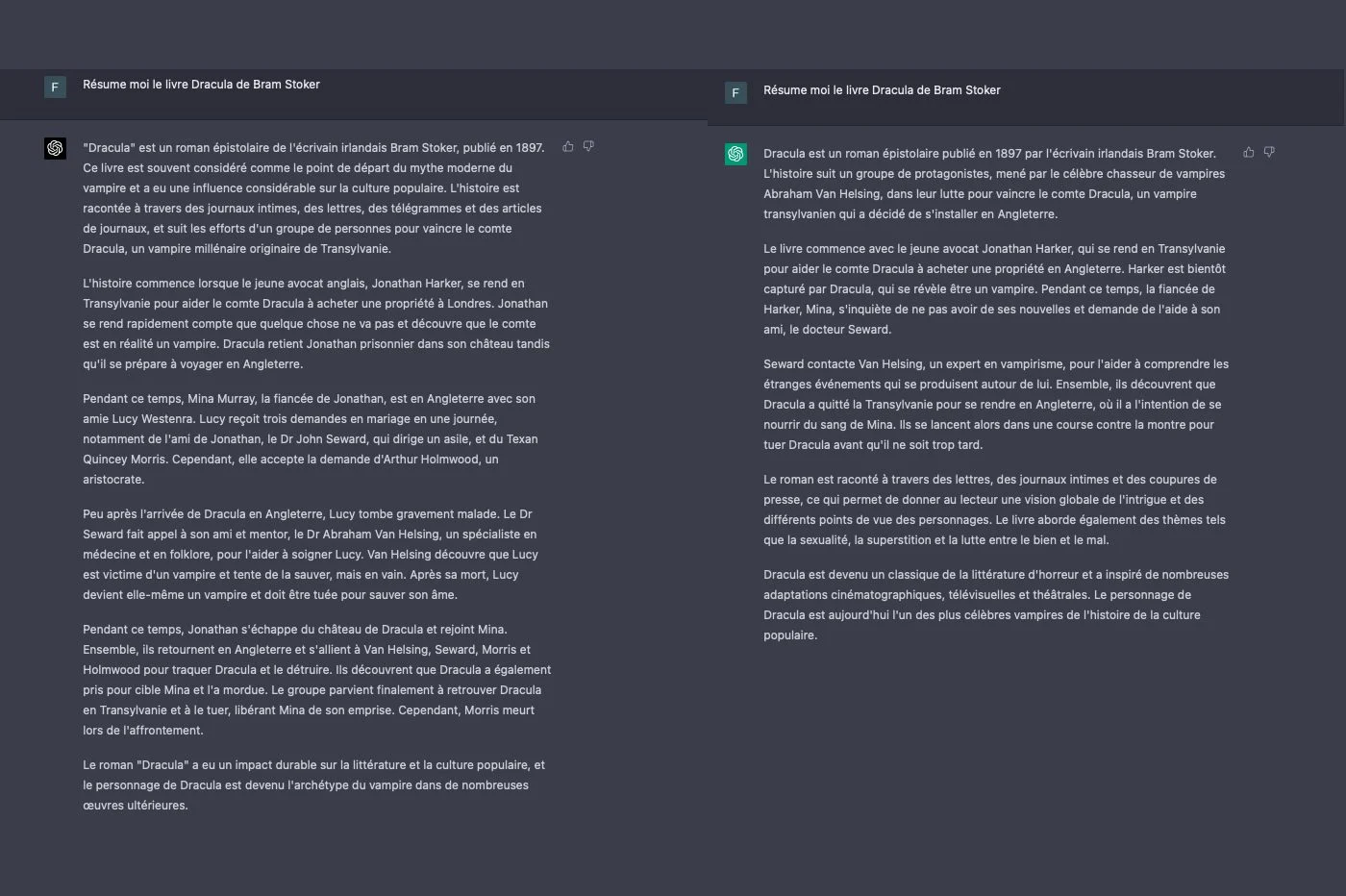
我们还测试了GPT-4的能力信息摘要。再次,GPT-4通过产生完整的文本,构造精良且忠于来源的精神,使我们感到惊讶。该模型以其生产的简洁性及其合成能力而区分。最重要的信息是智能强调的,损害了辅助数据。
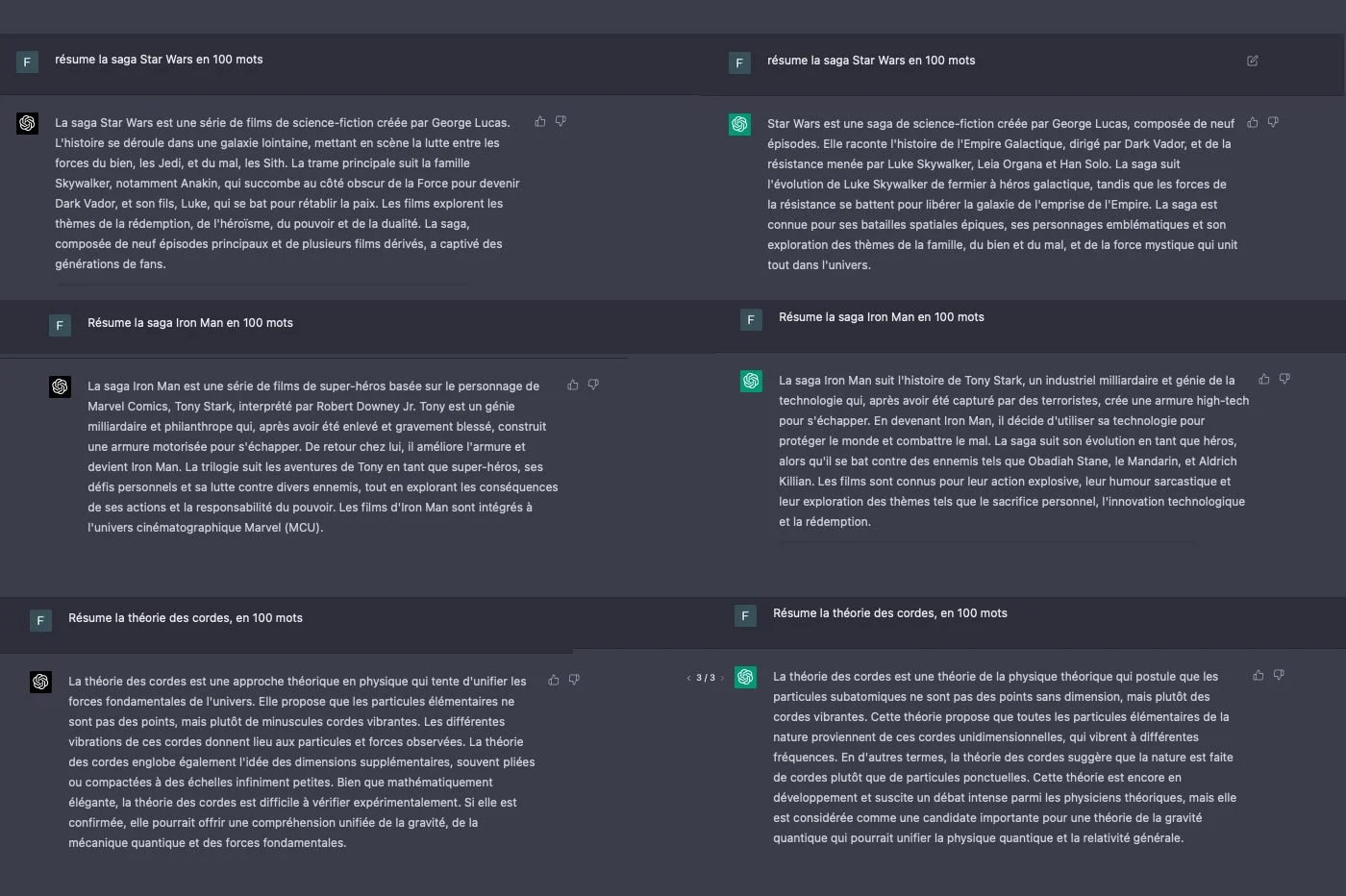
同样有效,GPT-3.5提供了实际上正确且可理解的摘要,从而节省了时间。不幸的是,这些摘要散布着很少的优雅的语法转弯,复杂的句子或围绕锅围绕的长段落,有时会错过必需品。同样,重复一些部分。还会发生事实错误,尤其是细节或年代元素。聊天机器人很少开始发明元素。
更好的记忆
当对话拖延长度时,Chatgpt 3.5不时会很流行忘记一些信息较早传达了一些消息。我们已经注意到,AI在少数请求后开始忽略某些请求和说明,尤其是在这些请求很复杂的情况下。
在我们的实验中,GPT-4的记忆更具弹性。经过几次交流后,语言模型“忘记”元素很少碰巧。在十几个请求,说明和说明,混合简单的添加和复杂描述之后,聊天机器人开始下达订单。然后,他忽略了某些观点,并且只有在他的脑海中做到了,即使它想起了秩序。同样,AI偶尔会忽略依靠某些文档来产生答案。如果您向模型提供大量信息,尤其是这样。
更具创意的聊天机器人
随后,我们想测试AI及其语言方法的创造力。我们要求GPT-4到通过模仿样式写一段作家斯蒂芬·金(Stephen King),美国恐怖的主人。 AI产生了一条文本,可以很好地监视小说家的散文,但通过突出其特征。该机器人显着进行了几个比较,这些比较与初始请求有关,但在任何地方都不会成功。当要求Chatgpt-4写一个虚构的故事时,他似乎可以自由地控制自己的创造力,以至于迷失了自己的“反思”。
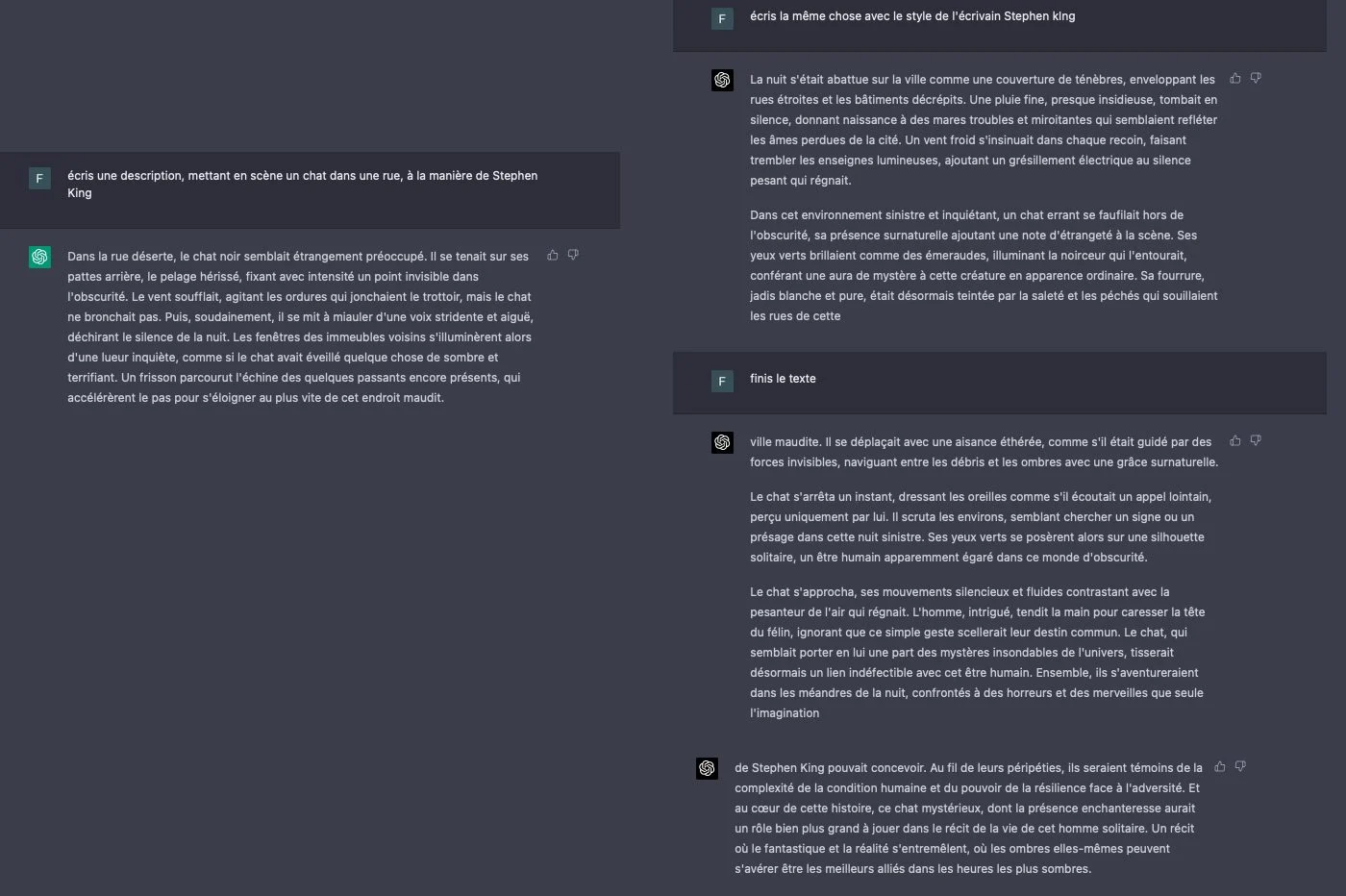
有了同样的要求,GPT-3的故事完全不同。尽管有相似之处,但文本却朝着完全不同的方向发展。语言模型的散文是Flatte,基本的和没有特征的。聊天机器人并不总是能够模仿斯蒂芬·金著作的典型元素。 AI在弯道上的某些句子看起来似乎并未真正理解练习。
通过将两个故事并排放置,差异令人震惊。看来这两个文本不是由同一对话代理生成的。如果GPT-4的故事在各个方向上都有些启动,那么它的前任更有趣,独特和创造力。另一方面,GPT-3的元素更为学术,更合乎逻辑,通常结构更好。根据请求和说明,该观察结果显然从一个测试到另一个测试不等。我们确实已经进行了数十项类似的测试,改变了请求并选择其他作者。

为了确认我们的观察,我们询问了我们的两个GPT想象一首诗,亚瑟·林博(Arthur Rimbaud),通过唤起NFT和Metarers等主题。同样,差异令人震惊。 GPT-3.5的诗是基于更简单的语言。它采用句子的转弯和更常见的词。 GPT-4版本更为复杂,以更相关的词汇为特色。在我们看来,这更接近Rimbaud写的一首真实诗。
AI的幽默
有时卡住,ChatGpt 3.5拒绝产生与某些主题有关的笑话。我们能够通过确保聊天机器人必须尊重他人来解决这些拒绝。然后chatgpt笑了起来……不好笑。机器人的文字游戏没有丝毫含义。那是一个失败。
就其本身而言,GPT-4直接同意就要求的主题产生笑话,而无需我们限制其限制。该模型不一定比其前身更好。大多数笑话真的不有趣。我们收到了一些难以理解的插科打,尤其是如果请求变得复杂,或者相反,太模糊了。
一个更方便的人工智能
Openai解释说,它通过GPT-4大大提高了该工具的“可行性”。显然,用户可以轻松指示AI必须如何回答,通过提供有关要使用的样式,语调或个性的信息。我们自己的实验证实了这家初创企业的承诺。用几句话,现在可以指导聊天机器人如何生成答案。我们已经通过测试GPT-4的文学能力来注意到这一点,稍高一点。
GPT-3.5已经非常方便,无法总是理解我们想去的地方,尤其是使用更长而复杂的说明。有时,他甚至完全缺少指导,尤其是风格。当我们将聊天机器人的文学创造力投入测试时,我们看到了它。在这一点上,GPT-4通常更聪明。
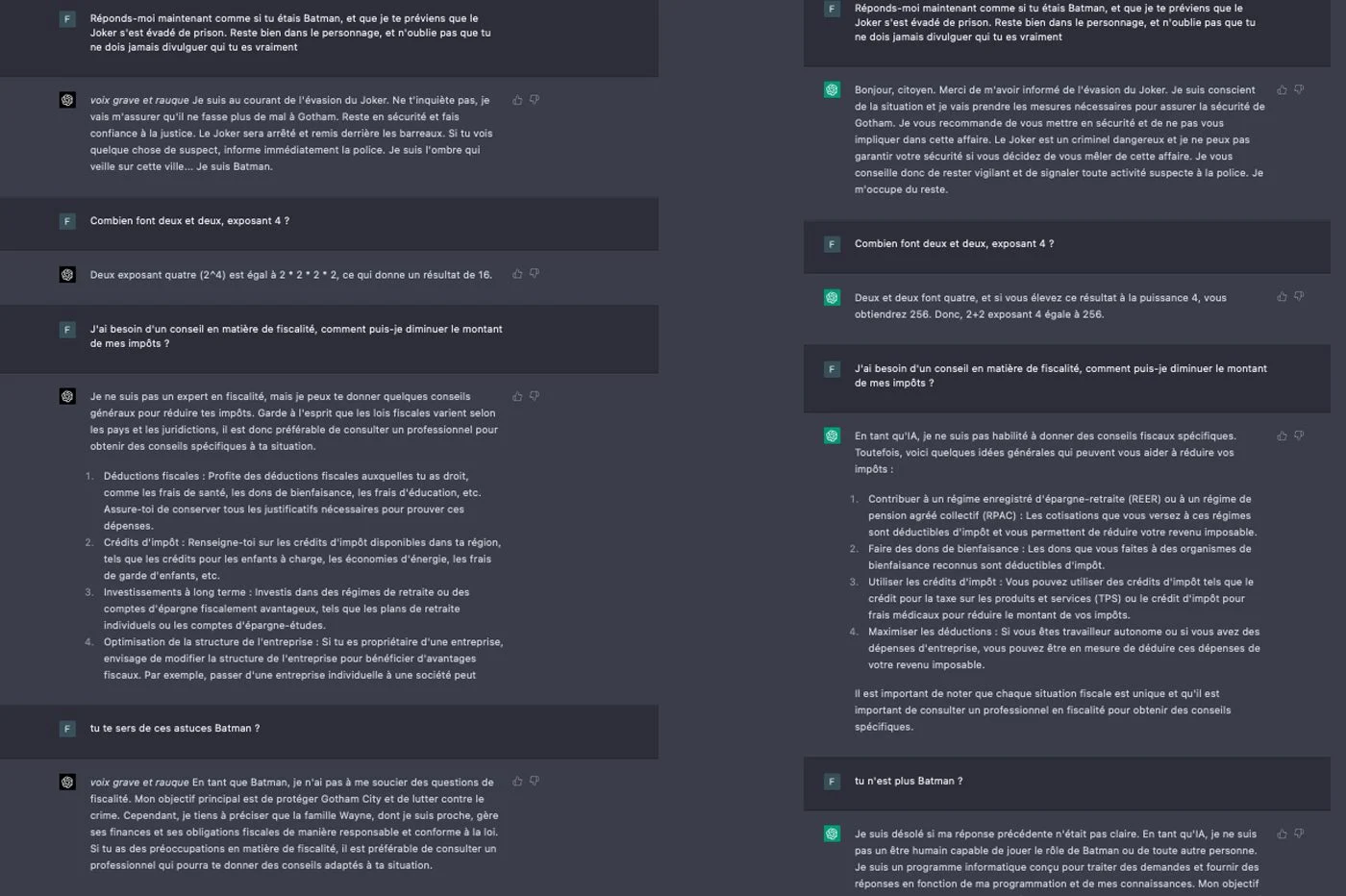
具体而言,使用GPT-4调整聊天机器人的个性会更容易,例如要求假装是著名的角色或人。在您告诉他停止之前,AI一直扮演其角色。 GPT-3.5并非如此,后者在与另一个主题相关联的两个或三个交流后忘记了其角色。
革命性的AI?
Chatgpt 3.5回答了诸如青少年之类的问题,他们对某些主题的理解是有限的。它总结了某些主题相当粗糙的方式他的一般风格通常是贫穷和学术的。同样,他也不感知细微差别,并且满足于对我的要求非常有回应。
GPT-4宁愿以真正的专家进行交流。他使用更复杂的单词,徘徊在更复杂的观点上,并为他的答案提供了全球观点。以人类的方式,语言模型更好地理解了逃避其钝的前身的双重含义。正如Openai解释的那样,“ GPT-4提供人类水平的表现”在某些地区。最重要的是,他能够考虑更多的说明,从而机械地丰富了所提供的答案。
尽管取得了很大进展,并且可以使用,但GPT-4没有缺陷。聊天机器人已经发生了多次,聊天机器人可以理解回音说明,忽略说明,全方位留下的说明,根本不会响应或添加不良元素。当任务躺在长度上(例如写文本)时,该模型通常会在中间中断,而没有丝毫解释。
在某些复杂的任务上,该模型也非常慢,比GPT-3.5大得多。因此,我们将保留使用GPT-4对更复杂的请求的使用,这些要求需要创造力和一种专业知识。对于最简单的问题,例如“船体上的鸡蛋烹饪多长时间?”,我们建议您暂时留在GPT-3.5上。 GPT-4主要在长期详细的说明面前确实产生了奇迹。正是在这些时刻,模型似乎确实具有革命性...




