Blackwell GPU ใหม่สำหรับศูนย์ข้อมูลมอบความสามารถในการประมวลผลที่เหนือกว่ารุ่น Hopper ในปัจจุบันอย่างมาก ความคลั่งไคล้ในโซลูชั่น NVIDIA ไม่หยุด...
ตามที่คาดไว้ NVIDIA หนึ่งในบริษัทที่ได้รับประโยชน์สูงสุดจากการเพิ่มขึ้นของ AI ได้รับประโยชน์จาก GTC (การประชุมเทคโนโลยี GPU) ซึ่งจะจัดขึ้นในสัปดาห์นี้ที่เมืองซานโฮเซ่ รัฐแคลิฟอร์เนีย เพื่อนำเสนอ GPU ใหม่ ยังกับ GeForce RTX 50 Seriesแต่ค่อนข้างBlackwell GPUs มีไว้สำหรับศูนย์ข้อมูลและบริษัทได้คาดการณ์ถึงความต้องการที่แข็งแกร่งมากแล้ว- Jensen Huang ซีอีโอของบริษัท จึงได้เปิดเผยรุ่นต่อจาก H100, H200 และ GH200: B100 และ B200 ซึ่งสอดคล้องกับสองรุ่นแรก เช่นเดียวกับ GB200 ที่สืบทอดมาจากรุ่นสุดท้าย
แบล็คเวลล์ ฉันไม่ผ่าน au MCM
คาดว่าจะมีมาหลายเดือนแล้ว และตอนนี้เป็นทางการแล้ว: สถาปัตยกรรม Blackwell ถือเป็นการนำการออกแบบ MCM มาใช้ (โมดูลมัลติชิป- AMD ใช้อยู่แล้ว โดยให้ความยืดหยุ่นมากกว่าการออกแบบเสาหินแบบเก่า Blackwell ได้รับประโยชน์จากกระบวนการ 4NP (4nm) ของ TSMC

แน่นอนว่าดาวดวงนั้นคือ B200 ตอบสนองความต้องการ คิดค้นโดย Jensen Huang“มี GPU ที่ใหญ่กว่า”เพื่อตอบสนองความต้องการของ generative AI บนเวที ชายในแจ็กเก็ตหนังเปรียบเทียบชิป Hopper กับ GPU ของ Blackwell โดยตรง และจริงๆ แล้ว มันมีขนาดที่แตกต่างกัน อย่างไรก็ตาม ในการป้องกันของ Hopper นั้น B200 ไม่ใช่ GPU ตัวเดียวในแง่ดั้งเดิม ประกอบด้วยชิปสองตัวที่ทำงานเป็น CUDA GPU แบบรวมศูนย์ เชื่อมต่อกันด้วยการเชื่อมต่อ NV-HBI (อินเทอร์เฟซแบนด์วิธสูง NVIDIA) เท่ากับ 10 ถึง/วินาที

โดยไม่รวมอยู่ในรายการค่า B200 มีทรานซิสเตอร์ 208 พันล้านตัว เทียบกับ 80 พันล้านสำหรับ H100 / H200 ชิปตัวนี้มีหน่วยความจำ HBM3e ขนาด 192 GB ที่ให้แบนด์วิธ 8 TB/s และมอบประสิทธิภาพ AI สูงกว่ารุ่นถึงห้าเท่า โดยเฉพาะอย่างยิ่ง Blackwell ให้ประสิทธิภาพต่อชิป 2.5 เท่าของรุ่นก่อนใน FP8 สำหรับการฝึก และ 5 เท่าใน FP4 สำหรับการอนุมาน อย่างไรก็ตาม โปรดทราบว่าความแม่นยำของ FP4 นั้นเฉพาะกับสถาปัตยกรรม Blackwell ใหม่ (ซึ่งเพิ่มรูปแบบ FP6 ใหม่ด้วย) ดังนั้นเราจึงต้องพึ่งพา FP8 แทนเพื่อเปรียบเทียบ Blackwell และ Hopper นอกจากนี้ ปริมาณการใช้ยังเพิ่มขึ้น โดยอยู่ที่ประมาณ 1,000 W ต่อชิป เทียบกับ 700 W สำหรับ Hopper GPU

นอกจากนี้ การเชื่อมต่อระหว่างกัน NVLink รุ่นที่ห้าซึ่งเร็วเป็นสองเท่าของ Hopper รองรับ GPU ได้มากถึง 576 ตัว
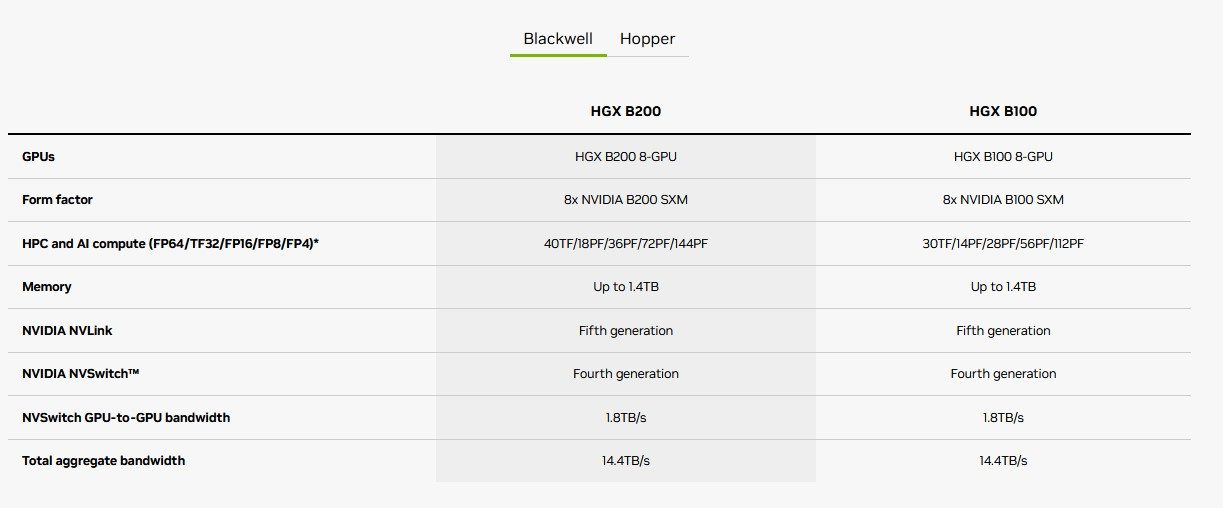
B100 ไม่มีสิทธิ์เข้าร่วมนิทรรศการเต็มรูปแบบเช่นนี้ ตามตัวเลขที่ระบุ สัญญาว่าจะมีประสิทธิภาพน้อยกว่ารุ่นเล็กน้อย NVIDIA กล่าวถึงสิ่งนี้สำหรับผลิตภัณฑ์บางอย่าง เช่น HGX B100s ที่กล่าวถึงด้านล่าง เพื่อนร่วมงานของเราจาก AnandTech แนะนำว่านี่เป็นชิปตัวเดียวที่มีทรานซิสเตอร์ถึง 104 พันล้านตัว แต่การยืนยันนี้จะต้องได้รับการยืนยัน
A B200 มีทุกรสชาติ
กลับมาที่ B200 ก็จะใช้ใน GB200 Grace Blackwell ด้วย เป็นลูกหลานของ GH200 Grace Hopper Superchip เราพบ B200 คู่หนึ่งที่เกี่ยวข้องกับ NVIDIA Grace CPU (72 Arm Neoverse V2 cores) ชุดนี้มี HBM3e สูงสุด 384 GB TDP คือ 2,700 วัตต์

เพื่อความสมบูรณ์ เรามาพูดถึงสเตชั่น DGX B200 ซึ่งมี B200 GPU แปดตัวและโปรเซสเซอร์ Intel Xeon Platinum 8570 สองตัว และเพื่อพูดคุยเกี่ยวกับ B100, HGX B200 และ HGX B100 ที่มาพร้อมกับ 8 B200 / B100 GPU ในรูปแบบ SXM (โมดูลเซิร์ฟเวอร์ PCI Express-
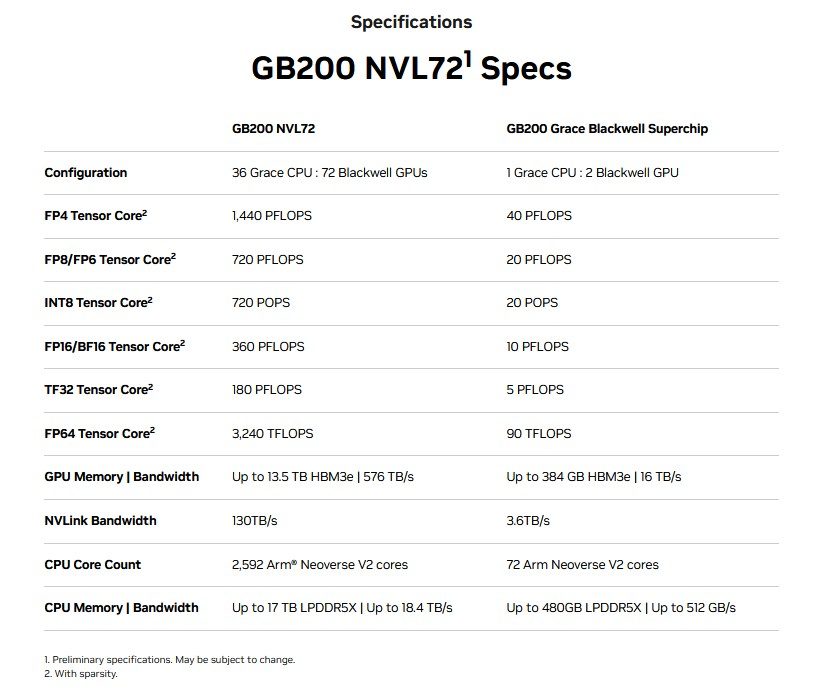
สุดท้าย เมื่อใช้ร่วมกับชิปอื่นๆ ที่เรียกว่า NVLink Switch ที่รับผิดชอบในการจัดการการเชื่อมต่อระหว่างกันของ NVLink GB200 จึงเป็นส่วนประกอบสำคัญของ GB200 NVL72 ซึ่งเป็นระบบแร็คสเกลแบบหลายโหนด ระบายความร้อนด้วยของเหลว ในเมนู: Grace CPU 36 ตัว และ GPU Blackwell 72 ตัว สำหรับประสิทธิภาพการฝึก AI 720 petaflops และประสิทธิภาพการอนุมาน AI 1.4 exaflops

เกี่ยวกับ GB200 NVL72 นั้น Jensen Huang กล่าวว่า:“มีเครื่องจักร Exascale เพียงไม่กี่เครื่อง หรืออาจจะสามเครื่องบนโลกนี้ ตามที่เราพูดกัน นี่คือระบบ AI ระดับ exascale ในแร็คเดียว”-
ปิดท้ายด้วยบันทึกวัฒนธรรมเล็กๆ น้อยๆ ชื่อของสถาปัตยกรรมของ NVIDIA นั้นเป็นเกียรติแก่ David Harold Blackwell มหาวิทยาลัยแคลิฟอร์เนีย นักคณิตศาสตร์ของ Berkeley ที่เชี่ยวชาญด้านทฤษฎีเกมและสถิติ และเป็นนักวิจัยผิวดำคนแรกที่ได้รับแต่งตั้งให้เข้าร่วมสถาบันวิทยาศาสตร์แห่งชาติ-
🔴 เพื่อไม่พลาดข่าวสาร 01net ติดตามเราได้ที่Google ข่าวสารetวอทส์แอพพ์-
แหล่งที่มา : NVIDIA





