โมเดลภาษาเป็นหัวใจสำคัญของตัวแทนการสนทนา เช่น ChatGPT ที่ผู้ใช้อินเทอร์เน็ตหลายล้านคนใช้ แบบจำลองภาษาอธิบายวิวัฒนาการของความเกี่ยวข้องของปัญญาประดิษฐ์ในด้านการประมวลผลภาษาธรรมชาติ (NLP) การแนะนำโดยย่อเกี่ยวกับการทำงานของแบบจำลองทางภาษาเหล่านี้ เช่น โมเดลภาษาขนาดใหญ่ (LLM) จะช่วยให้เราได้รับคำจำกัดความได้ดีขึ้น
ปัญญาประดิษฐ์กำลังประสบกับคลื่นแห่งความเป็นประชาธิปไตยเป็นประวัติการณ์ต้องขอบคุณการมาถึงของตัวแทนสายสนทนาอย่างChatGPT- พวกเขาทำให้สามารถแสดงแง่มุมที่น่าทึ่งที่สุดประการหนึ่งของขีดความสามารถของการเรียนรู้เชิงลึกและปัญญาประดิษฐ์แก่สาธารณชนทั่วไปได้ ผ่านการสาธิตการใช้ภาษาของมนุษย์อย่างเหมาะสมและพูดคุยกับพวกเขาโดยไม่ต้องอยู่ข้างๆ จาน
คุณคงสงสัยอย่างแน่นอนแล้วว่าในช่วงเวลาอันสั้นนี้ เราเปลี่ยนจากความสัมพันธ์กับเครื่องจักรผ่านโค้ดไปสู่ภาษาธรรมชาติที่เรียบง่ายนี้ได้อย่างไร ซึ่งเพียงแต่ขอให้ตัวเองจินตนาการว่ากำลังพูดคุยกับมนุษย์คนอื่น นี่คือจุดที่โมเดลภาษาเข้ามามีบทบาท ในขณะที่ยังคงเป็นโมเดลคอมพิวเตอร์ที่ใช้เวกเตอร์และฟังก์ชัน มันจะทำหน้าที่เป็นบัฟเฟอร์ระหว่างสองเอนทิตีที่ดูเหมือนทุกอย่างจะแยกจากกัน: มนุษย์และเครื่องจักร
ความรู้เบื้องต้นเกี่ยวกับรูปแบบภาษา
โมเดลภาษาจึงเป็นระบบคอมพิวเตอร์ที่มีภารกิจในการแปลภาษาธรรมชาติสู่เครื่องและให้เครื่องเข้าใจ วิเคราะห์ และตอบสนองต่อคำขอ แปล สรุป แต่ยังจำลองจินตนาการ สะท้อน และคำนึงถึงสิ่งใดบ้าง ก่อนหน้านี้ไม่สามารถจัดวางและตั้งทฤษฎีในรูปแบบของฟังก์ชัน: ความแตกต่างทางวัฒนธรรมความรู้สึกและอารมณ์
ตั้งแต่ปี 2017 การปฏิวัติได้เกิดขึ้นพร้อมกับการเพิ่มขึ้นของ LLM (โมเดลภาษาขนาดใหญ่) เช่น Transformers ของ Google ซึ่งผลักดันความเกี่ยวข้องของการทำความเข้าใจข้อความและการตอบสนองต่อภาษาธรรมชาติให้อยู่ในระดับที่ไม่เคยมีมาก่อน จากนี้ไป แบบจำลองทางคณิตศาสตร์ที่ผลิตโดยเครื่องจักรจะผสานเข้ากับความฉลาดของมนุษย์อย่างแท้จริง กลืนข้อมูลจำนวนมหาศาล และสร้างความสามารถในการตอบสนองต่อพารามิเตอร์นับพันล้านตัว
คำต่างๆ จะไม่ถูกวิเคราะห์หรือสร้างขึ้นทีละคำอีกต่อไป: เครื่องจักรสามารถจัดการคำสั่งโดยรวมได้ในเวลาไม่นาน และเสนอการวิเคราะห์ สรุป การแปล หรือแม้แต่การแก้ไขและการทดสอบได้เร็วกว่ามนุษย์คนใดๆ
อภิธานศัพท์
เพื่อให้สามารถเข้าสู่คำจำกัดความของรูปแบบภาษาและสบายดีเพื่อให้สามารถอธิบายวิธีการทำงานของตัวแทนการสนทนาได้ เราจะต้องใช้สำนวนและคำศัพท์เฉพาะ ก่อนที่เราจะเริ่ม เรามาลองสร้างอภิธานศัพท์สั้นๆ กันก่อน
แชทบอท:ที่รู้จักกันทั่วไปในชื่อ "แชทบอท" เป็นแอปพลิเคชั่นที่ให้คุณส่งข้อความสอบถามและรับการตอบกลับ ChatGPT และกูเกิล เบิร์ดเป็นตัวแทนการสนทนาโดยใช้ AI และโมเดลภาษา ก่อนหน้านี้ แชทบอทอาจถูกจำกัดในรูปแบบเช่นผู้ช่วยดิจิทัล
ข้อมูลตามลำดับ:ทุกประโยค ย่อหน้า เอกสาร เป็นตัวอย่างข้อมูลตามลำดับ ในการประมวลผลภาษาธรรมชาติ ลำดับของคำในประโยคหรือหน่วยข้อความอื่นๆ เป็นสิ่งจำเป็นสำหรับการทำความเข้าใจความหมายโดยรวม
ทางเข้าและออก:โดยทั่วไปรายการจะเป็นข้อมูลตามลำดับที่ส่งโดยผู้ใช้อินเทอร์เน็ต ผลลัพธ์คือข้อมูลตามลำดับที่สร้างโดยเครื่องโดยคำนึงถึงอินพุตและพารามิเตอร์อื่นๆ เช่น ข้อมูลลำดับก่อนหน้า ข้อมูลโมเดลภาษาที่ได้รับจากการฝึกอบรม เป็นต้น
การตั้งค่า:เพื่อให้สามารถเข้าใจ วิเคราะห์ และเสนอการตอบสนองต่ออินพุต แบบจำลองทางภาษาจึงใช้พารามิเตอร์ทั้งชุด ซึ่งได้มาจากการฝึก AI พารามิเตอร์เหล่านี้เรียกว่าน้ำหนักซึ่งมีการปรับตามตัวอย่างในฐานข้อมูล ยิ่งมีพารามิเตอร์มากเท่าไร โมเดลภาษาก็จะยิ่งสามารถวิเคราะห์อินพุตและให้เอาต์พุตที่ซับซ้อนมากขึ้นเท่านั้น
NLP (การประมวลผลภาษาธรรมชาติ) :ความเชี่ยวชาญทุกด้านในด้านการประมวลผลภาษาธรรมชาติ ซึ่งอาจเกี่ยวข้องกับการแปล การสรุป การสร้าง หรือแม้แต่การจัดหมวดหมู่ข้อความ เครื่องมืออย่าง ChatGPT นำองค์ประกอบทั้งหมดเหล่านี้มารวมกัน

การกำหนดโมเดลภาษาสำหรับ AI
โมเดลภาษาที่อยู่เบื้องหลังตัวแทนการสนทนาประเภท ChatGPT หรือ Bard คือระบบที่ช่วยให้เครื่องเข้าใจและสร้างข้อความในภาษาธรรมชาติของมนุษย์ เพื่อให้สามารถพูดในภาษา เข้าใจบริบท รู้สึกถึงน้ำเสียงและรายละเอียดปลีกย่อยอื่น ๆ ด้านวัฒนธรรม เรียนรู้รูปแบบและเสนอคำตอบที่เกี่ยวข้อง โมเดลภาษาจะต้องอาศัยข้อมูลจำนวนมาก และรู้วิธีการประมวลผลและนำไปใช้อย่างถูกต้อง มันด้วยการป้อนข้อมูลของผู้ใช้
โมเดลภาษาที่จำกัดบางโมเดลใช้งานได้กับโมเดลทางสถิติล้วนๆ ในขณะที่โมเดลอื่นๆ เช่น LLM ทำงานกับแมชชีนเลิร์นนิง โมเดลภาษาที่ทันสมัยที่สุดมีทั้งความสามารถในการวิเคราะห์ความสัมพันธ์ระหว่างคำและกลุ่มของคำทั้งหมด บริบท และเก็บลำดับข้อความก่อนหน้าไว้ในหน่วยความจำเพื่อพิจารณาบริบทชั่วคราว มันอาศัยพารามิเตอร์อื่นๆ มากมายและนำเทคนิคอื่นๆ เข้ามา เช่น “โทเค็น” และ “มาสก์”
โมเดลภาษาเป็นหัวใจสำคัญของการประมวลผลของตัวแทนการสนทนา โดยจะถูกนำมาใช้เมื่อข้อความของผู้ใช้ถูกแปลงเป็นชุดตัวเลข ที่เรียกว่าเวกเตอร์ ที่จะวิเคราะห์ผ่านข้อมูลหลายประเภท โมเดล n-grams เป็น LLM รวมถึงเครือข่ายที่เกิดซ้ำ บทบาทของมันจะสิ้นสุดลงในขณะที่ข้อความที่สร้างขึ้นโดยเครื่อง จากนั้นจึงแสดงบนหน้าจอของผู้ใช้อินเทอร์เน็ต
บทบาทของเวกเตอร์
ในทุกกรณี แบบจำลองเหล่านี้เป็นแบบจำลองทางคณิตศาสตร์ที่ทำนายความน่าจะเป็นที่คำหรือลำดับของคำจะปรากฏในประโยค โมเดลเหล่านี้จึงผ่านการประมวลผลด้วยคอมพิวเตอร์จริง ไม่ใช่เรื่องมหัศจรรย์ พวกเขาแปลโดยใช้โมเดลอัลกอริธึม ซึ่งเกี่ยวข้องกับระบบในการแปลงอินพุตเป็นตัวเลข ก่อนที่จะแปลงกลับเป็นข้อความสำหรับเอาต์พุต
ในระหว่างนี้ พวกมันจะกลายเป็นลำดับของตัวเลขที่เรียกว่าเวกเตอร์ ใน NLP เวกเตอร์เหล่านี้ทำให้สามารถจัดหมวดหมู่ที่สัมพันธ์กับคำอื่นได้เป็นพิเศษ และด้วยเหตุนี้จึงสร้างคะแนนความใกล้เคียงระหว่างคำเหล่านั้น จำนวนหลักในเวกเตอร์จะกำหนดจำนวนขนาดของแบบจำลอง เวกเตอร์เหล่านี้มีส่วนชี้ขาดในการกำหนดความหมายของแต่ละคำ ทำให้ภาษาธรรมชาติเป็นภาษาทางคณิตศาสตร์ และท้ายที่สุดก็ทำให้สามารถเลียนแบบความเข้าใจของมนุษย์และภาษาของมันได้
เมื่อเวลาผ่านไป เวกเตอร์ก็เริ่มถูกนำมาใช้เพื่อคำนึงถึงประเด็นที่ละเอียดอ่อนมากขึ้นของภาษาธรรมชาติ เช่น การเสียดสี อารมณ์ อารมณ์ขัน
บทบาทของปัญญาประดิษฐ์
โมเดลภาษาเป็นองค์ประกอบสำคัญในโลกแห่งปัญญาประดิษฐ์ของการประมวลผลภาษาธรรมชาติ (NLP) แล้วอะไรคือบทบาทของปัญญาประดิษฐ์- เพื่อให้สามารถสร้างแบบจำลองทางภาษาที่มีคุณภาพได้ จะต้องคำนึงถึงข้อมูลจำนวนมหาศาล หากเพียงเพื่อสร้างการจำแนกประเภทของคำระหว่างกัน ความคล้ายคลึง ความแตกต่าง ฯลฯ ในการทำเช่นนี้ โครงข่ายประสาทเทียมทำให้สามารถทำงานขนาดยักษ์ที่มนุษย์จะทำได้อย่างง่ายดายและในเวลาที่บันทึกได้
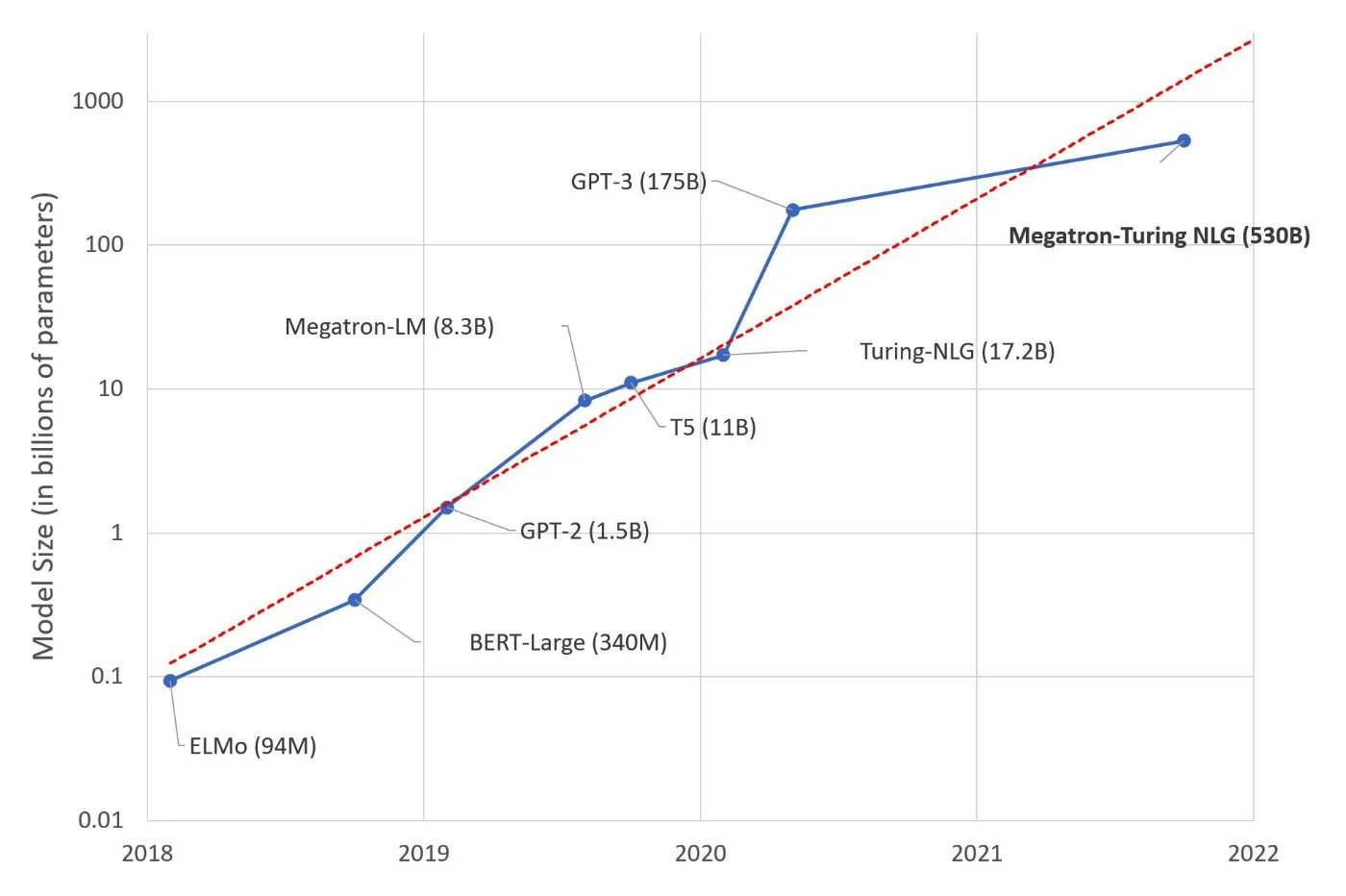
ตำแหน่งของ AI ในแบบจำลองภาษาจึงพบได้เป็นพิเศษในการฝึกอบรมจากข้อมูลที่เป็นข้อความจำนวนมาก โดยทั่วไป LLM จะได้รับการฝึกอบรมล่วงหน้าในชุดคำมากกว่า 10,000 พันล้านคำ (10B) โดยเฉพาะอย่างยิ่งจาก Common Crawl, The Pile, MassiveText, Wikipedia และ GitHub แต่ปัญญาประดิษฐ์ก็ยังปรากฏอยู่ในภายหลัง เพื่อช่วยให้โมเดลสามารถเสนอการตอบสนองตามบริบทและชาญฉลาด และโดยเฉพาะอย่างยิ่งโดยการเรียนรู้อย่างต่อเนื่อง
ปัจจุบัน ความสามารถของโมเดลภาษาได้ก้าวหน้าไปพร้อมกับการเรียนรู้ของเครื่องและแม้แต่การเรียนรู้เชิงลึก โมเดลภาษาเข้าถึงได้การตั้งค่า 70 B บน Llama 2 โดย Metaและ 175 พันล้านบน GPT-3 ของ OpenAI สิ่งสำคัญที่คนทั่วไปรู้จัก (และใช้) คือโมเดลภาษาขนาดใหญ่(LLM) แต่เพื่อให้ได้สิ่งที่เรารู้ในปัจจุบัน โมเดลเหล่านี้อาศัยโมเดลอื่นๆ ที่มีข้อจำกัดมากกว่า แต่แต่ละโมเดลได้มีส่วนร่วมในการออกแบบ LLM
บทบาทของเครือข่ายที่เกิดซ้ำ
ก่อนที่จะมาถึงแบบจำลอง LLM ที่เรารู้จักในปัจจุบัน แบบจำลองทางภาษามีพื้นฐานมาจากแนวคิดของเครือข่ายที่เกิดซ้ำก่อน โมเดลเหล่านี้ประมวลผลข้อมูลข้อความเป็นตัวเลขและวิเคราะห์แต่ละเวกเตอร์ของแต่ละคำด้วยเวกเตอร์ความคิด เวกเตอร์ความคิดเป็นไปตามหลักการเดียวกัน และด้วยเหตุนี้จึงมีการปรับแต่งหลังจากเพิ่มคำใหม่แต่ละคำในประโยค เช่นเดียวกับสมองของมนุษย์ที่ในระหว่างการอ่านจะค้นพบความหมายของประโยคคำแล้วคำเล่าและทำให้เกิดความคิดของประโยคเนื่องจากแต่ละคำที่อ่านติดต่อกัน เครือข่ายที่เกิดซ้ำจึงสามารถมีความเข้าใจที่ดีและนำเสนอความเกี่ยวข้องและมากขึ้น เอาต์พุตในบริบทด้วยเวกเตอร์นี้
บทบาทของทรานส์ฟอร์มเมอร์ส
โมเดลภาษาขนาดใหญ่ (LLM) ไม่ได้มาถึงในชั่วข้ามคืน มีเวอร์ชันที่ได้รับการปรับปรุงหลายเวอร์ชันระหว่างพวกเขากับเครือข่ายที่เกิดซ้ำ ซึ่งพยายามแก้ไขข้อบกพร่องในการทำความเข้าใจแบบจำลอง โดยเฉพาะอย่างยิ่งเนื่องจากขีดจำกัดของหน่วยความจำและการถ่วงน้ำหนักความสำคัญของคำ เราสามารถอ้างอิงหน่วยความจำระยะสั้นระยะยาว (LSTM) และ Gated Recurrent Unit (GRU) ได้อย่างโดดเด่น แต่การปฏิวัติที่แท้จริงของโมเดลภาษานั้นเกิดขึ้นในปี 2560 และการนำเสนอโมเดล Transformers โดยนักวิจัยของ Google ซึ่งนำไปสู่การเกิดขึ้นของหลักการ LLM ที่ได้รับความนิยมมากที่สุด
Transformers แตกต่างจากเครือข่ายที่เกิดซ้ำในแนวทาง: แทนที่จะวิเคราะห์แต่ละคำ กลับวิเคราะห์ทั้งประโยคหรือชุดประโยค การถ่วงน้ำหนักของเวกเตอร์แต่ละตัวที่เชื่อมโยงกับคำ จากนั้นจะผ่านหลักการของโทเค็นและมาสก์ Transformers เป็นสถาปัตยกรรมที่ช่วยให้มีวิธีใหม่ในการสร้างแบบจำลองข้อมูลบริบทและข้อมูลข้อความ ก็เพียงพอแล้วที่จะยกเลิกปัญหาเรื่องความจำ สถานที่ของคำในประโยค การสร้างความสัมพันธ์ของคำที่ไม่ใช่ท้องถิ่น
“มาสก์” มีลักษณะเป็นสองประเภท: ตัวกรองเชิงสาเหตุ ซึ่งมีอิทธิพลต่อเวกเตอร์หนึ่งมากกว่าอีกเวกเตอร์หนึ่ง ขึ้นอยู่กับบริบทของประโยค และตัวกรองการขยาย ซึ่งไม่มีอิทธิพลต่อความเข้าใจหรือการตอบกลับ แต่อนุญาตเฉพาะประโยคที่มีความยาวต่างกันเท่านั้น ทำให้เป็นประโยคที่มีขนาดเท่ากัน (เรายังคงอยู่ในคณิตศาสตร์ ทุกอย่างต้องเป็นสี่เหลี่ยมจัตุรัส) โดยการเพิ่มคำ... ซึ่งไม่มีประโยชน์ และไม่ควรนำมาพิจารณาโดยเครื่อง
ในส่วนของโทเค็นนั้น ช่วยเพิ่มคุณค่าของเวกเตอร์ของเครือข่ายที่เกิดซ้ำโดยการเพิ่มสิ่งต่าง ๆ มากมายที่ต้องพิจารณาและมิติแบบสองทิศทางในการทำความเข้าใจแต่ละคำ ตัวอย่างเช่น มีสัญลักษณ์ของคุณลักษณะ (เรียกว่า "การฝัง") ซึ่งเพิ่มชั้นความสนใจซึ่งให้น้ำหนักความสำคัญของแต่ละคำในประโยค และสร้างการเชื่อมโยงระหว่างแต่ละคำโดยไม่ทำให้ความหมายโดยรวมซับซ้อนมากขึ้น . โมเดลภาษาที่แตกต่างกันยังคงเพิ่มประสิทธิภาพโทเค็นเหล่านี้และการประมวลผลต่อไป
Google ซึ่งเปิดตัว BERT เป็นครั้งแรก ได้เปิดตัว LaMDA (หรือที่เขียนว่า Lambda) และสุดท้ายคือ PaLM (สำหรับความเข้าใจภาษาทั่วไปและการบูรณาการแหล่งข้อมูลหลายแหล่ง) OpenAI ยังใช้โมเดลหม้อแปลงที่มี GPT-3, GPT-3.5 และ GPT-4 โมเดลภาษาเวอร์ชันแรกเริ่มตั้งแต่ปี 2018 วันนี้GPT-4โดดเด่นด้วยอินพุตจำนวนมาก (ไม่จำกัดเฉพาะอินพุตข้อความและยังยอมรับรูปภาพหรือเสียงด้วย) และพารามิเตอร์จะมีขนาดใหญ่กว่าน้ำหนัก 175 พันล้านของ GPT-3 มาก
ขีดจำกัดของโมเดลภาษา
เราต้องแยกแยะสองสิ่ง: ขีดจำกัดของโมเดลภาษาและขีดจำกัดของโมเดลภาษาโดยทั่วไป การตั้งคำถามเกี่ยวกับแบบจำลองภาษาประเภทหนึ่งนั้นแตกต่างจากการตั้งคำถามถึงความสามารถเชิงวิวัฒนาการของแบบจำลองภาษาโดยรวม
อย่างไรก็ตาม จะมีวิธีแก้ปัญหาที่จะดำเนินการแตกต่างไปจากเดิมอย่างสิ้นเชิงเมื่อต้องโต้ตอบกับเครื่องโดยใช้ภาษาธรรมชาติหรือไม่? จนถึงปัจจุบัน โมเดลภาษาทั้งหมดมีขีดจำกัด แต่หนทางในการปรับปรุงยังคงเกี่ยวข้องกับหลักการโดยรวมแบบเดียวกันของโมเดลภาษาและการเพิ่มคุณค่าของอัลกอริทึม... ยังห่างไกลจากการเปรียบเทียบใดๆ กับจิตวิญญาณและจิตสำนึกของมนุษย์
หลักการของแบบจำลองทางภาษายังคงขึ้นอยู่กับการฝึกอบรมที่มีคุณภาพโดยสามารถเข้าถึงข้อมูลที่สำคัญแต่ไม่จำกัด (เนื่องจากขาดทรัพยากรคอมพิวเตอร์ที่จำเป็น) ในขณะเดียวกัน โมเดลภาษาก็ไม่รู้อะไรเลย พูดอย่างเคร่งครัด พวกเขาเพียงแต่ทำการเปรียบเทียบและไม่จดจำ ด้วยเหตุนี้ การตอบสนองที่คิดค้นขึ้นจึงมีความเหนือกว่า ซึ่งมักถูกเปรียบเทียบกับ "ภาพหลอน"
ท้ายที่สุดแล้ว การดูโมเดลทางภาษาเพื่อทำความเข้าใจตัวแทนการสนทนานั้นคล้ายคลึงกับการเปิดประตูของศูนย์ข้อมูลเพื่อทำความเข้าใจการทำงาน (และขีดจำกัด) ของอินเทอร์เน็ต ความมหัศจรรย์ที่ ChatGPT มอบให้ในปัจจุบันสามารถอธิบายได้ และผลของงานก็กลับมาสู่ระบบที่เสร็จสมบูรณ์ ซึ่งมนุษย์จินตนาการและนำไปใช้
ที่ Meta การพัฒนาปัญญาประดิษฐ์เป็นเรื่องราวของภาษาฝรั่งเศสบางส่วน หลังจากทำงานร่วมกับ Jérome Pesenti เป็นเวลาหลายปี นักวิจัยและผู้ชนะรางวัล Yann LeCun Touring Prizeเมื่อเดือนมิถุนายนที่ผ่านมาได้กล่าวถึงโมเดลทางภาษาใหม่ที่เรียกว่าเจปา(“Joint Embedding Predictive Architecture”) ที่มีความก้าวหน้าครั้งใหญ่“เครื่องจักรอย่างน้อยก็ฉลาดพอ ๆ กับมนุษย์”อธิบายหัวหน้าฝ่ายวิจัยทางวิทยาศาสตร์เกี่ยวกับ AI ภายในบริษัทแม่ของ Facebook ด้วย JEPA สถาปัตยกรรมโมเดลภาษาจะคำนึงถึงปัจจัยใหม่ๆ ด้วย“เข้าใจโลกเบื้องลึก”-
“ทุกวันนี้ แมชชีนเลิร์นนิงห่วยมากเมื่อเทียบกับสิ่งที่มนุษย์สามารถทำได้ […] จึงมีบางสิ่งที่ยิ่งใหญ่หายไปจากเรา”ยานน์ เลคุน กล่าวเสริม ซึ่งไม่ได้สับเปลี่ยนคำพูดของเขาและยังประกาศเช่นนั้นอีกด้วย“AI และการเรียนรู้ของเครื่องในปัจจุบันห่วยจริงๆ มนุษย์มีสามัญสำนึกแต่เครื่องจักรไม่มี”สำหรับเขา เส้นทางที่ต้องมุ่งความสนใจไปที่เหนือสิ่งอื่นใดคือแง่มุมด้านความรู้ความเข้าใจ ซึ่งก็คือการทำงานของสมองมนุษย์ โมเดลภาษามุ่งเน้นไปที่ทฤษฎีภาษาอย่างง่ายและน้ำหนักของคำมากเกินไป
บทสรุป: เมื่อกลอุบายจะตามเรามาจริงๆ
ต้องขอบคุณโมเดลภาษาที่ทำให้ปัญญาประดิษฐ์ได้เรียนรู้วิธีการพูด จากแบบจำลอง n-grams ถึงโมเดลภาษาขนาดใหญ่(LLM) เป็นศูนย์กลางของตัวแทนการสนทนา และท้ายที่สุดก็เป็นเรื่องที่น่าประหลาดใจอย่างยิ่งที่ผู้ใช้อินเทอร์เน็ตค้นพบด้วยการเปิดตัว ChatGPT เมื่อปลายปีที่แล้ว แม้ว่า Google, Meta, OpenAI และอื่นๆ อีกมากมายกำลังปรับปรุงเทคโนโลยีของตนเอง แต่ทุกวันนี้พวกเขาล้วนอาศัยตรรกะของระบบโมเดลภาษา เพื่อให้สามารถเชื่อมต่อมนุษย์กับเครื่องจักรในภาพลวงตาของการสนทนาระหว่างคนสองคนที่เกือบจะสมบูรณ์แบบ
อย่างไรก็ตาม ในการสนทนา เราต้องการเชื่อมโยงเอฟเฟกต์ดังกล่าวว้าวไปจนถึงปัญญาประดิษฐ์ในความหมายกว้างๆ โดยไม่ต้องอ้างอิงและอธิบายการทำงานของระบบการถอดความภาษาธรรมชาติเป็นลำดับตัวเลข เวกเตอร์ของ "โทเค็น" ซึ่งผู้สร้างรู้จักเป็นอย่างดี, ของ“มาสก์” ของอินพุตและเอาท์พุตที่ไม่เกี่ยวข้องกับการเรียนรู้ทางปัญญาเพียงเล็กน้อย แต่พอได้รับการวิพากษ์วิจารณ์ โมเดลภาษายังคงเป็นเพียงผู้เดียวที่นำเสนอเครื่องมือการสนทนาและเครื่องมืออื่นๆ ในสาขา NLP เพื่อให้บรรลุความทะเยอทะยานของตน
ตรรกะทางปัญญาและคอมพิวเตอร์ควอนตัม
ดังนั้นเราจึงเลียนแบบการอนุมาน การวิเคราะห์ และการไตร่ตรอง... แต่ผลลัพธ์ที่เสนอโดยตัวแทนการสนทนา แม้ว่าพวกเขาจะหลอกลวง แต่ก็ทิ้งความลับของกลอุบายของพวกเขาไว้บ้าง ในอนาคตโมเดลภาษาจะต้องเพิ่มขนาดและความสามารถในการดำเนินงานต่อไป ในอนาคตอันใกล้นี้ ช่องทางที่ดีที่สุดในการปรับปรุงคือฮาร์ดแวร์: การมาถึงของคอมพิวเตอร์ควอนตัมจะทำให้โมเดลภาษาและ AI ก้าวไปไกลกว่าระดับปัจจุบัน
โมเดลทั้งหมดในปัจจุบันไม่เท่ากัน และบางโมเดลกลับไปสู่พื้นฐานของตรรกะเมื่อเราเผชิญกับขีดจำกัด: การมุ่งเน้นไปที่เป้าหมายเดียวและละทิ้งปัญญาประดิษฐ์ระดับโลก ซึ่งเป็นตัวแทนการสนทนาที่มีคำตอบสำหรับทุกสิ่ง บริษัทหลายแห่งจะพบว่าการมุ่งเน้นเฉพาะด้านนั้นน่าสนใจกว่า โดยเฉพาะอย่างยิ่งในการวิจัย (เช่นการวิจัยทางการแพทย์และชีววิทยา) และชุมชนที่แบ่งปันแนวคิดและความก้าวหน้าร่วมกันเกี่ยวกับโมเดลโอเพ่นซอร์สกำลังประชุมกันบนแพลตฟอร์มที่รู้จักกันดีในโลก AI:กอดหน้า-
ที่เราจะต้องดูคือขีดจำกัดของโมเดลภาษาที่เขียนขนาดใหญ่ การตั้งคำถามถึงการดำรงอยู่ของมันคือการตั้งคำถามถึงแก่นแท้ของวิธีการทำงานของ NLP จนถึงปัจจุบัน จากนั้น ระบบใหม่อาจถือกำเนิดขึ้นและครอบคลุมระบบที่ใหญ่กว่า ซึ่งคราวนี้จะพยายามจำลองและเลียนแบบความรู้ความเข้าใจเฉพาะของมนุษย์ จากนั้นเคล็ดลับมายากลจะยิ่งใหญ่ขึ้น - ภาพลวงตาจะไม่ใช่กระต่ายในหมวกอีกต่อไป แต่เป็นตัวนักมายากลเอง
เราจะยึดติดกับเวทมนตร์ตลอดไปหรือไม่?
🔴 เพื่อไม่ให้พลาดข่าวสารจาก 01net ติดตามเราได้ที่Google ข่าวสารetวอทส์แอพพ์-







