在过去的几年中,Deepfake视频一直存在,有些人通过使用不同的演员来操纵电影和电视场景在其中找到了一些乐趣,但是通过人工智能操纵现实生活的镜头也可能非常危险,因此Deepfake探测器在事实检验和拍摄医护视频方面非常有用。
但是,据加州大学圣地亚哥分校的计算机科学家称,事实证明,这种工具可以被击败。
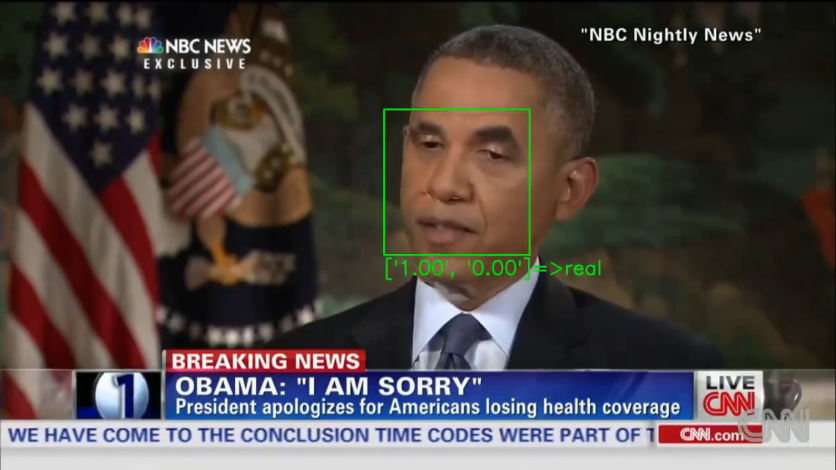
使用“对抗示例”
在一份报告中新闻18,可以通过添加称为“对抗性示例”的输入来使DeepFake探测器被愚弄,这些输入略微操纵输入。
对抗性的例子导致人工系统(如机器学习模型)犯错误,认为深深的视频从未被触摸过,并且根据加州大学圣地亚哥分校的科学家的说法,尽管压缩了虚假视频,但该攻击仍然可以奏效,这应该能够删除虚假功能。
基本上,探测器可以通过专注于面部特征(例如眼动动作)来确定伪造的视频,这些视频通常在操纵视频中繁殖不佳。
不幸的是,这种方法甚至可以欺骗最复杂的检测器。
令人震惊的证据是在2021年1月5日至1月9日举行的有关计算机视觉应用(WACV)2021的应用的上一场冬季会议上展出的。
“可能是现实世界的威胁”
计算机工程博士学位Shehzeen Hussain说:“我们的工作表明,对DeepFake探测器的攻击可能是现实世界中的威胁。”加州大学圣地亚哥分校的学生,以及UCSD Jacobs工程学院的WACV纸的第一任学生在线报纸。
侯赛因进一步说:“更令人震惊的是,我们证明,即使对手可能不了解探测器使用的机器学习模型的内部运作,也可以在强大的对抗性深层制作。”
根据该报告,即使在注入对抗性例子时,科学家也能够打败甚至最复杂的探测器的警惕。
高成功率
为了测试攻击,研究人员创建了两种情况:一种可以完全访问检测器模型的情况,包括分类模型的体系结构和参数以及面部提取管道;还有另一个只能查询机器的地方。
在第一种情况下,科学家在未压缩视频中取得了99%的成功率,压缩录像带的成功率为84.96%。
在第二种情况下,未压缩视频的成功率为86.43%,压缩文件为78.33%。
科学家说,这是第一次证明探测器可以被击败的证据。
因此,本文背后的科学家正在鼓励对软件进行改进的培训,以更好地检测此类操作,建议一种与他们所谓的对抗性训练相似的方法,其中自适应对手不断产生新的深击,而探测器则继续学习检测操纵样品。
他们还拒绝释放使用的代码,以免被敌对政党使用。
本文由技术时报拥有
撰写者:NHX Tingson








