最近几个月主要是LLM(大语言模型)谁一直走在最前线,ChatGPT 等解决方案的头条新闻或者双子座。然而,这些庞然大物都有一个缺陷:它们的庞大性,参数数量非常多;在本地管理它们是一项挑战。因此,在巨人的阴影下,人工智能语言模型更温和的发展;它们在逻辑上被称为 SLM,因为小语言模型。在这些幼芽中,我们发现了 Google 的 Gemma 2B 和 7B、Anthropic 的 Claude 3 Haiku 甚至 Meta 的 Llama 3 8B 等物种。微软刚刚发布了一款新产品:Phi-3 Mini。
Phi-3 Mini,三重奏的第一个代表
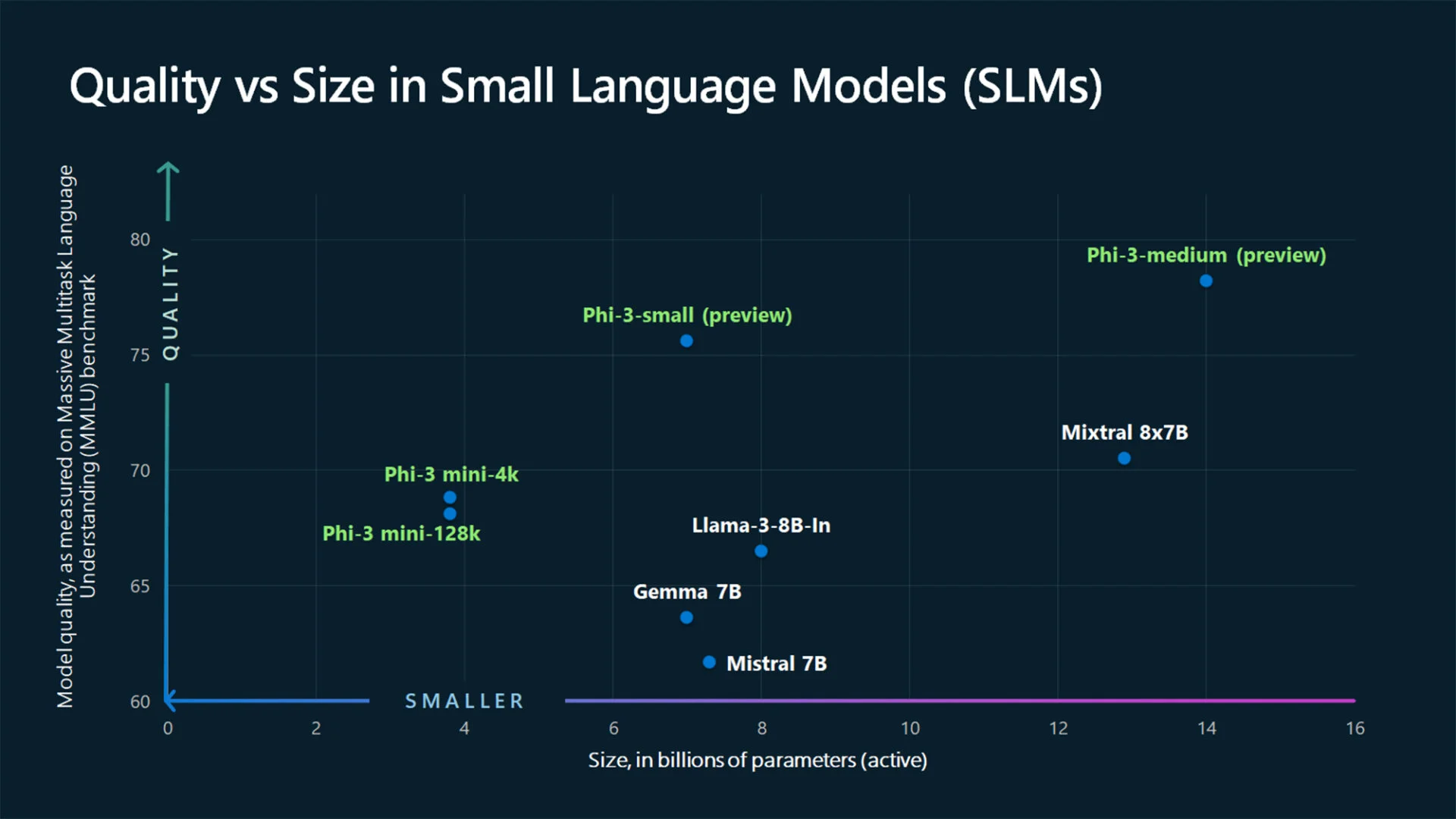
Phi-3 Mini 是第一个公开的三种子字符串代表;另外两个预计在未来几个月推出,分别是 Phi-3 Small 和 Phi-3 Medium。从参数数量来看,这些模型分别需要 38 亿、70 亿和 140 亿的土壤。此外,正如您对数字 3 所了解的那样,已经有先例:Phi-1 和 Phi-2,后者于去年 12 月首次亮相。
尽管尺寸很小,Phi-3 Mini 的效率却并不低。微软声称它提供的性能比两倍大小的型号更好。在致我们同事的声明中边缘,微软 Azure AI 平台副总裁 Eric Boyd 补充道“Phi-3 Mini 与 GPT-3.5 等 LLM 一样高效,但格式更小”。
使用 LLM 培训的 SLM
正如您可以想象的那样,SLM 模型要想高效,就必须经过良好的训练。虽然 LLM 是通过互联网上收集的大量数据收集的,但对于 SML 来说,这种收集并不相关。因此,微软团队采用了不同的方法来训练 Phi-3 Mini。“为什么不搜索非常高质量的数据,而不是对原始网络数据进行训练呢? »微软负责生成人工智能研究的副总裁 Sébastien Bubeck 总结道。
然而,正如该公司指定的那样,如果“区分高质量信息和低质量信息对人类来说并不困难”(一个有争议的断言),对于语言模型来说更是如此,除非另有证明,否则它只是一个没有任何推理能力的数据吸尘器。也就是说,为了进行初步的整理以及相关信息的选择,微软使用了LLM。据该公司介绍,一种新型训练器解释了 Phi-3 Mini 的卓越性能。
“当前一代大型语言模型的强大功能确实是我们以前在生成合成数据方面所没有的工具”微软研究院 AI 前沿实验室主任 Ece Kamar 强调道。基本上,我们找到了一些埃皮纳勒大师和学生的形象,第一个将他的知识的一部分提炼到第二个。
事实上,小型人工智能模型的运行成本比大型人工智能模型更便宜,最重要的是,在当前的硬件状态下,可以促进本地使用。
微软解释如下:该公司写道,由于 SLM 能够离线运行,更多的人将能够以迄今为止不可能的方式使用人工智能。如果说在万物互联的时代,通过服务器请求强大的聊天机器人似乎并不是不可逾越的障碍,那么这实际上是来自一个生活在网络基础设施相对发达的国家的城市居民的言论:雷德蒙德公司只是简单地提到了这个案例缺乏蜂窝服务的农村地区;更具体地说,一个农民的例子,在检查农作物并在叶子或树枝上发现疾病迹象时,将能够使用配备视觉能力的 SLM 拍摄相关农作物的照片,从而立即获得有关以下问题的建议:如何治疗寄生虫或疾病——诊断和治疗大概由拜耳直接决定,但这是另一个争论。
微软人工智能副总裁 Luis Vargas 描绘了一个理想世界:“如果您所在的地区没有良好的网络,您仍然可以从设备上的人工智能体验中受益”;这要归功于 SLM。喜乐啊!
来源 : 微软







