语言模型是数百万互联网用户所使用的对话代理人作为一种CHATGPT的核心,解释了人工智能在自然语言治疗领域(NLP)中相关性的演变。这些语言模型(例如大语言模型(LLM))的功能的小启动将使更好地识别定义成为可能。
人工智能正在经历民主化的风空前的,由于对话代理的到来,例如chatgpt。他们可以向公众展示深度学习和人工智能能力的最壮观方面之一:通过演示以适合人类的语言,并与他们讨论而不在盘子旁边。
当然,您已经想知道,在很少的时间内,我们与机器的关系基本上是通过代码与这种简单的自然语言花费的,这只要求被想象与另一个人交谈。语言模型在这里发挥作用,同时使用向量和功能保留计算机模型,它可以作为两个实体之间的缓冲区,这些实体似乎是分开的:人类和机器。
语言模型简介
因此,语言模型是计算机系统的使命,其使命是将自然语言翻译成机器,并允许其理解,分析和响应请求,翻译,总结,同时模拟想象力,反思并考虑到以前无法以功能形式进行示意性和理论化的内容:文化的细微差别,感觉和情感。
自2017年以来,一场革命随着LLM的兴起而出现(大型语言模型),例如Google的变形金刚,它在无与伦比的层面上推动了文本理解和对自然语言的响应的相关性。从现在开始,机器制作的数学模型与真正的人类智能,吞咽天文数量的数据合并并建立了其在数十亿个参数上的响应能力。
这些词不再是一个接一个地分析或生成的:该机器设法立即采取了一定的观点,并提出了分析,摘要,翻译甚至更正,并且比任何人都要快得多。
词汇表
能够进入语言模型的定义和很好能够解释对话代理的工作原理,我们将不得不使用特定的表达式和词汇。在开始之前,让我们尝试制作一个小词汇表。
会话代理:更常见的是“聊天机器人”,这是一个允许发送文本查询并获得答案的应用程序。 chatgpt和Google吟游诗人是基于AI的对话代理和语言模型。以前,与数字助手一样,会话代理可能会受到更大的限制。
顺序数据:所有句子,段落,文档都是顺序数据的示例。在对自然语言的处理中,句子或其他文本单元中的单词顺序对于理解全球含义至关重要。
入口和输出:输入通常是Internet用户发送的顺序数据。输出是计算机生成的顺序数据,考虑到输入和其他参数,例如先前的顺序数据,由于其培训的训练,获得的语言模型的数据等等。
设置:为了能够理解,分析和提出对条目的答案,语言模型使用了一组参数,这些参数是通过训练AI获得的。这些权重参数被称为,根据数据库的示例进行了调整。参数越多,语言模型应该能够更好地分析条目并提供更复杂的输出。
NLP(自然语言处理):自然语言治疗纪律的所有能力领域。可以是翻译,摘要,生成或文本分类。诸如chatgpt之类的工具将所有这些元素汇总在一起。

AI语言模型的定义
隐藏在Chatgpt或Bard对话代理后面的语言模型是一个系统,它允许机器理解并生成自然语言的文本,即人类的文本。为了能够用一种语言说话,了解上下文,感受基调和任何其他微妙的,文化方面,学习模式并提出相关响应,语言模型必须依靠大量数据,并知道如何处理并正确应用其与用户的输入正确应用。
当其他有限的语言模型(例如LLM)使用自动学习时,一些有限的语言模型在纯统计模型上起作用。最成功的语言模型都可以分析所有单词和单词,上下文组之间的关系,并在记忆中保持先前的文本序列,以考虑到时间的上下文。它依赖于更多参数,并带来其他技术,例如“令牌”和“蒙版”。
语言模型是对话剂的计算机心脏:它们在Internet用户的文本输入转换为一组图形时发挥作用,这些图形称为向量,可以通过多种类型的编码器来分析解码器,根据从N-gram模型转变为LLM模型,通过Rellm Maverrriver网络,解码器的解码器进行了分析。他的角色在计算机生成的文本出口时结束,然后显示在Internet用户的屏幕上。
向量的作用
在所有情况下,这些模型都是数学模型,可以预测单词或单词序列出现在句子中的概率。因此,模型经过真实的计算机处理 - 这不是魔术。它们由算法模型反映,因此暗示系统将条目转换为数字,然后再将其转换为文本以进行郊游。
同时,它们成为称为向量的数字。在NLP中,这些向量特别使得对与其他单词有关的分类有可能,从而在它们之间建立邻近分数。向量中的数字数确定了模型的尺寸数。这些矢量是决定每个单词的含义,制作自然语言数学的含义,并允许结束的人类理解及其语言。
随着时间的流逝,向量也开始被用来考虑更微妙的自然语言点:例如含义,情感,幽默。
人工智能的作用
语言模型是自然语言待遇(NLP)宇宙宇宙中的核心要素。什么是人工智能的作用?为了能够构成质量的语言模型,有必要考虑到巨大的数据,即使只是在它们之间建立单词的分类,它们的相似性,差异等。为此,神经网络使得人类会毫不费力地和创纪录的时间做泰坦尼克号的工作。
因此,从大量的文本数据生成LLM的培训中发现了AI在语言模型中的位置,可以预先训练超过1000亿个单词(10b),该单词超过1000亿个单词(10b),堆,堆,Massivetext,Wikipedia和github。但是,当时也出现了人工智能,以帮助模型提供上下文和智能答案,并尤其继续学习。
如今,随着机器学习甚至深度学习的到来,语言模型的能力已经发展。语言模型达到META上的70 B参数Openai GPT-3和1750亿。公众(和二手)已知的主要是大型语言模型(LLM),但是为了实现我们今天所知道的,这些模型依赖于其他模型,但每个模型都将自己的石头放在LLM的设计中。
重复网络的角色
在我们今天知道的LLM模型之前,语言模型首先支持重复网络的概念。这些模型以现金方式处理文本数据,并用思想向量分析每个单词的每个向量。思想向量遵循相同的原理,因此在句子中添加每个新单词后进行了完善。就像人的大脑一样,在阅读过程中,在一个句单词的词语中发现了单词短语的含义,并允许您想到一个句子,感谢每个单词读取以下单词,因此,重复的网络可以很好地理解并提供更多相关的郊游,并且在上下文中,由于该向量。
变压器的作用
大型语言模型(LLM)并未在一夜之间到达。它们之间和重复网络之间出现了几个改进的版本,这些版本试图纠正理解模型的故障,尤其是由于单词的重要性的内存限制和加权。我们可以显然提到长期的短期记忆(LSTM)和封闭式复发单元(GRU)。但是,语言模型的真正革命可以追溯到2017年,以及Google研究人员对变压器模型的呈现,这导致了最流行的LLM原则的出现。
变形金刚在其方法中与重复网络不同:它没有分析每个单词,而是分析整个句子或一组句子。然后,与单词相关的每个矢量的加权需要令牌和遮罩的原理。变形金刚是一种架构,允许一种新的方法来建模上下文数据和文本数据。是什么消除了记忆问题,句子中的单词的位置,以建立单词的非本地关系。
“面具”的特征是在两种:因果过滤器下,以影响向量,而不是根据句子的上下文来影响矢量,而填充过滤器对理解或响应没有影响,但仅允许在数学上添加数学的句子的句子的句子不同(我们必须是正方形的),但只能使不同长度的句子归一化(我们都必须添加)...被机器考虑在内。
同时,代币通过在理解每个单词时添加更多的考虑和双向维度来丰富重复网络的向量。例如,有很多特征(称为“嵌入”),这些特征被添加到关注层中,这将每个单词的重要性都放在句子中,并在每个单词之间建立链接而不会使整体含义复杂化。不同的语言模型继续优化这些令牌及其处理。
Google首先揭幕了Bert,此后一直推出LAMDA(也写了Lambda),最后是Palm(用于对语言的广义理解和几种信息来源的整合)。 OpenAI还基于具有GPT-3,GPT-3.5和GPT-4的变压器模型。其语言模型的第一个版本可追溯到2018年。GPT-4以更多的条目(不限于文本条目,也接受图像或音频)来区分,参数将大大远大于GPT-3的1750亿重量。
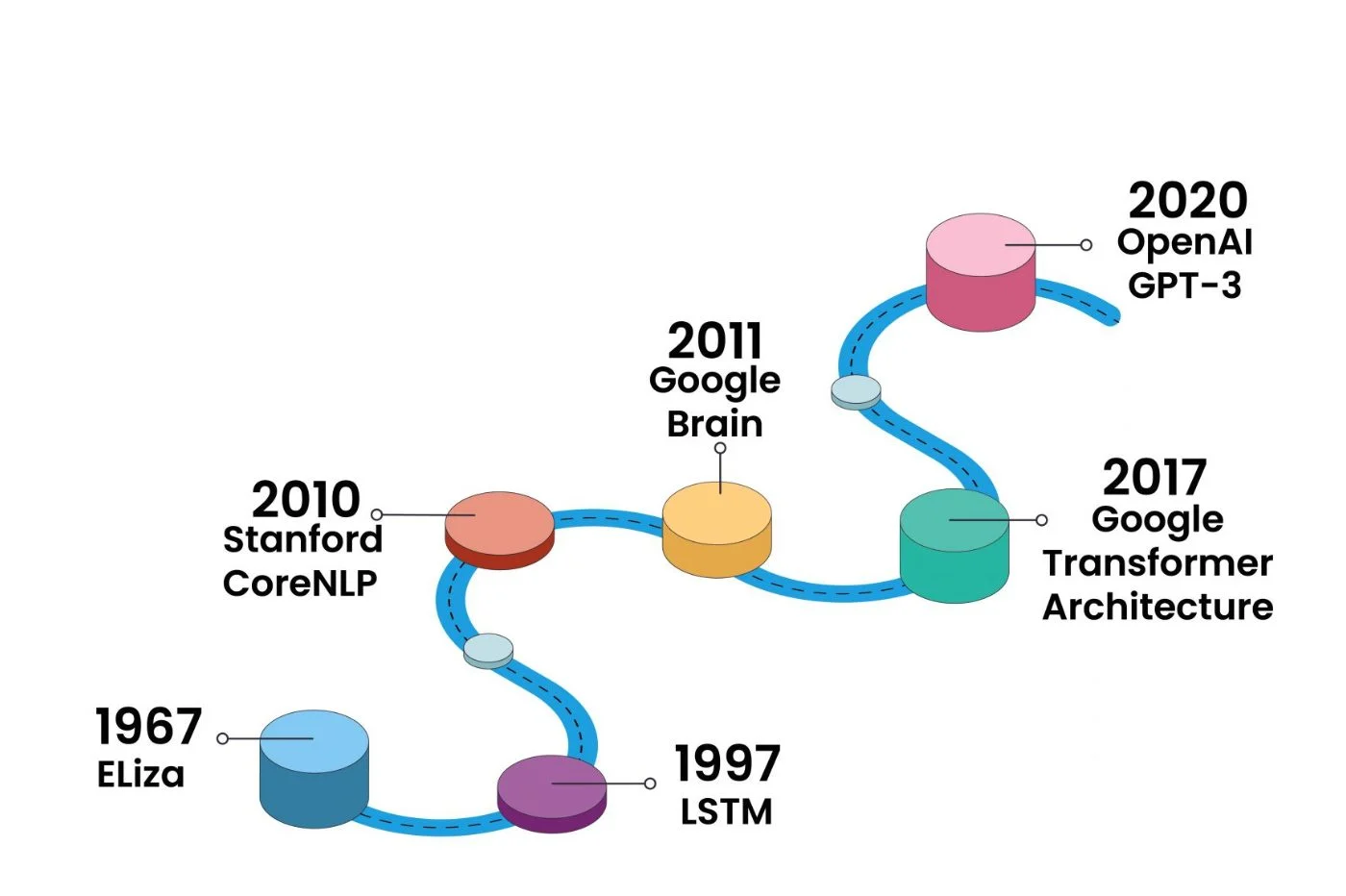
语言模型的限制
我们必须区分两件事:语言模型的限制和一般语言模型的限制。质疑一种语言模型的类型不同于质疑整个语言模型的演变能力。
但是,有一些解决方案可以通过自然语言与机器的交互作用完全不同?迄今为止,所有语言模型都有其限制,但是任何改进轨道仍然遵循语言模型和算法丰富的全球原理……与灵魂和人类意识的任何比较远非如此。
语言模型的原理仍然特别依赖于获得大型数据的质量培训,但不是不确定的(由于缺乏必要的IT资源)。同时,严格来说,语言模型一无所知。他们只是满足于制作类比而不记住的内容。因此,与“幻觉”相比,更普遍的发明响应优势。
最后,研究以了解对话代理的语言模型类似于打开数据中心的门,以了解互联网的功能(和限制)。今天解释了Chatgpt的魔力,并且他的作品果实是由于人类想象和实施的完成的系统。
在Meta,人工智能的发展是一个部分法国故事。在与研究人员和研究人员JéromePesenti合作了几年之后巡回赛Yann Lecun Prix Prix奖的获胜者去年6月解决了一种新的语言模型的主题JEPA(“嵌入预测架构”),主要进步“机器至少像人类一样聪明,如果不是人类”,解释说,在Facebook母公司内AI的科学研究的负责人。使用JEPA,语言模型的体系结构将考虑到“了解基本世界”。
“今天,机器学习确实与人类可以做的事情相关。 […]因此,巨大的东西逃脱了我们”,Yann Lecun补充说,他没有咀嚼他的话,也宣布“今天的AI和自动学习确实为零。人类在机器时具有常识。”对他来说,倾斜的曲目高于所有认知方面,即人脑的功能。语言模型对语言的简单理论和单词的重量过于徘徊。
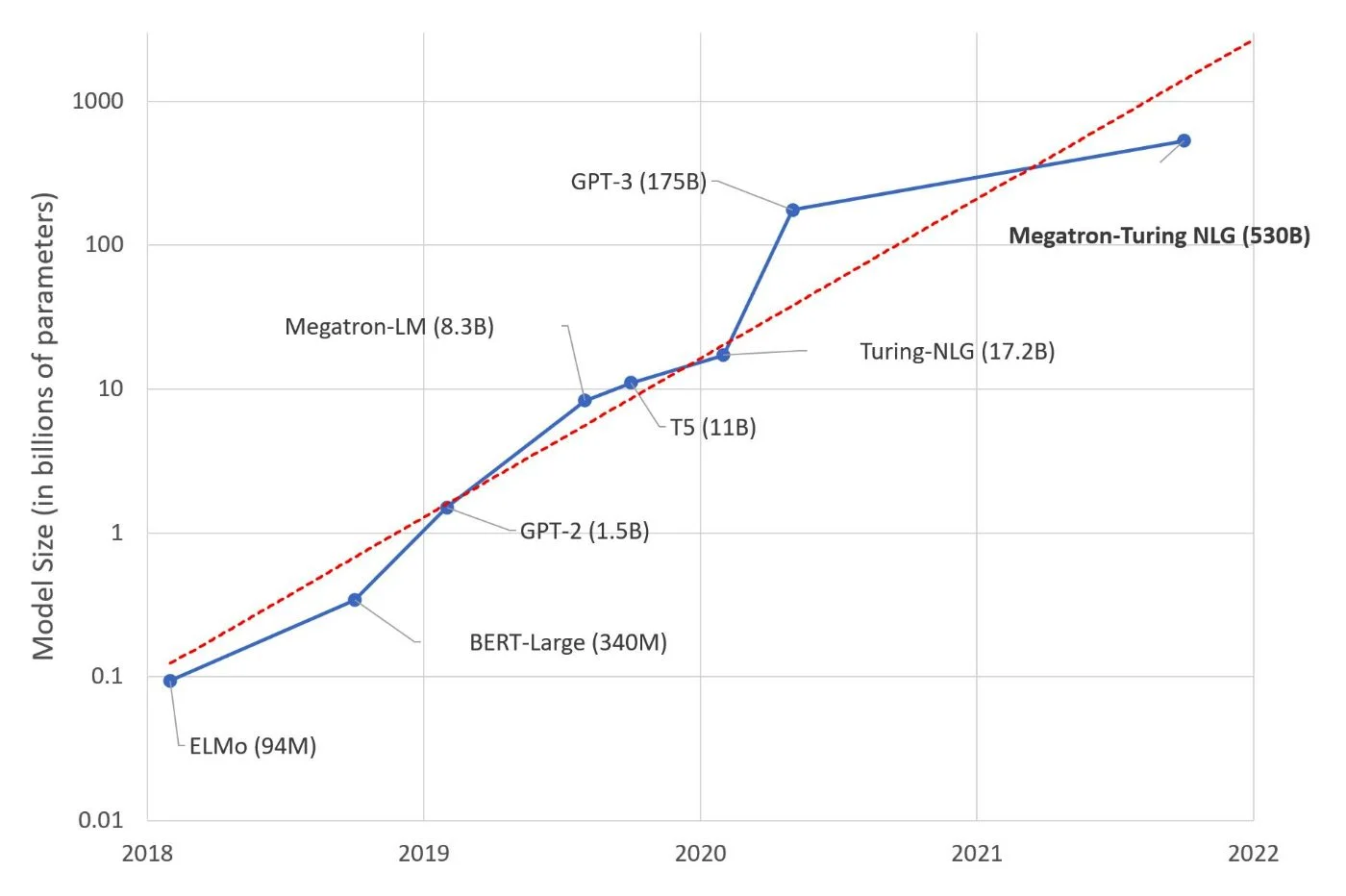
结论:当魔术回合真正超越我们时
多亏了语言模型,人工智能学会了如何说话。从n-gram模型到Larges语言模型(llm),他是对话代理商的中心,最终,他是互联网用户在去年Chatgpt年底发现的真正惊喜。如果Google,Meta,OpenAI和许多其他人都完善了自己的技术,那么所有人都依靠语言模型系统的逻辑,以便能够以两个人之间的对话几乎完美地将人类与机器联系起来。
但是,在讨论中,我们更喜欢附加效果哇从广义上讲人工智能,而无需引用和解释其创作者的功能,以自然语言转录系统的形象,“令牌”向量的自然语言转录系统, 的“面具”,条目和郊游与认知学习无关。但是,批评的停战,语言模型是现在仍然是唯一在NLP领域提供对话代理和其他工具的雄心手段的人。
认知逻辑和量子计算机
我们模仿了推论,分析,反思……但是,尽管他们虚张声势,但他们提出的结果使他们有些秘密,但他们的魔术圈又一点点秘密。因此,将来,语言模型将不得不继续获得维度和运营能力。在日益近距离的未来,通过硬件将是最大的改进轨道:量子计算机的到来将允许语言模型和AI超出当前量表。
迄今为止的所有模型都不相等,面对限制时,有些模型恢复了逻辑的基础:专注于一个目标并抛弃整体人工智能 - 拥有一切的对话代理。许多公司会发现指定一个领域更有趣,尤其是在研究中(AS医学和有机研究)以及在开源模型上共享思想和进步的社区已经在AI世界中的一个知名平台上开会:拥抱脸。
我们必须看的地方,它在广义上是语言模型的限制。质疑它的存在是质疑迄今为止NLP功能的核心。从那里开始,新系统可能会出现并包含更广泛的系统,该系统将寻求模拟和模仿人类特有的认知能力。从那里开始,魔术圈将变得更大 - 幻想将不再是帽子里的兔子,而是魔术师本人。
顺便说一句,我们总是会留下魔术吗?







