AMD 的 SLM
與該領域的其他巨頭一樣,AMD 也已進軍 SLM(小語言模型,小語言模式)及其開源模式 AMD-135M。該公司在 9 月 17 日發布的技術部落格中詳細介紹了這一點;她現在透過一篇更廣泛的公開文章揭露了這一點。 AMD-135M 也可透過 HuggingFace 和 GitHub 取得。
這個小語言模型屬於 Llama 家族(它正是基於 LLaMA2 架構)。它有兩個版本:AMD-Llama-135M 和 AMD-Llama-135M-code。
兩者都依賴推測解碼。這種方法的基本原理是什麼?使用一個小的初步模型產生一組潛在的代幣,然後透過更大的目標模型進行驗證。
AMD-135M 使用 AMD Instinct MI250 加速器對 6700 億個令牌進行了訓練。由於有四個 MI250 節點(每個節點有四個 MI250 加速器),該過程需要六天。 AMD 表示,它使用 SlimPajama 和 Project Gutenberg 資料集(包含 70,000 多本免費電子書的函式庫)來預訓練這個 1.35M 的模型。
AMD-Llama-135M-code 變體已使用 200 億個專門用於編碼的代幣進行了改進。在四個 MI250 加速器上完善此程式碼花了整整四天的時間。
SLM 與 LLM
我們已經解釋過了微軟在部署Phi-3 Mini流程中SLM相對於LLM的優勢。如果您需要一些回顧,有關 AMD-135M 的原始文章提供了一些有趣的見解。無論如何,要了解有關此主題的更多信息,請隨時諮詢我們定義 AI 語言模型的文件。
文件回顧說,儘管法學碩士很重要,“較小的語言模型 (SLM) 有一個令人信服的案例,它為平衡性能和操作約束提供了實用的解決方案”。正如您從上文中了解到的,雖然訓練 LLM 通常需要各種高階 GPU,但 SLM 提供了另一種解決方案。此外,該出版物還強調“雖然有一種方法可以獲得訓練有素的法學碩士,但通常很難在計算資源非常有限的客戶端設備上有效地運行它”。此外,AMD 還強調了其 SLM AMD-135M 的推理解碼優勢,不僅適用於 Instinct MI250 加速器,還適用於消費性硬件,在本例中為 Ryzen 9 PRO 7940HS。
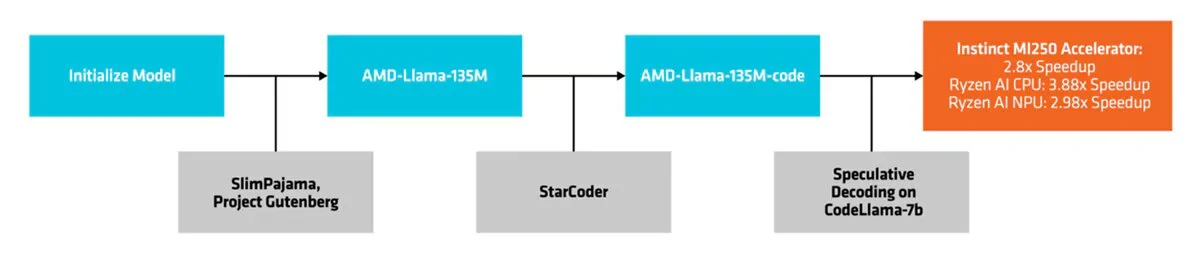
最後,AMD 聲稱,在沒有用數字壓倒你的情況下“性能可與市場上最受歡迎的型號相媲美”(Llama-68M 和 Llama-160M;GPT2-124M;OPT-125M)用於 Hellaswag、WinoGrande、SciQ、MMLU 和 ARC-Easy 中的 AMD-135M 模型。

來源 : AMD





