最近幾個月主要是LLM(大語言模型)誰一直走在最前線,ChatGPT 等解決方案的頭條新聞或者雙子座。然而,這些龐然大物都有一個缺陷:它們的龐大性,參數數量非常多;在本地管理它們是一項挑戰。因此,在巨人的陰影下,人工智慧語言模型更溫和的發展;它們在邏輯上被稱為 SLM,因為小語言模型。在這些幼芽中,我們發現了 Google 的 Gemma 2B 和 7B、Anthropic 的 Claude 3 Haiku 甚至 Meta 的 Llama 3 8B 等物種。微軟剛剛發布了一款新產品:Phi-3 Mini。
Phi-3 Mini,三重奏的第一個代表
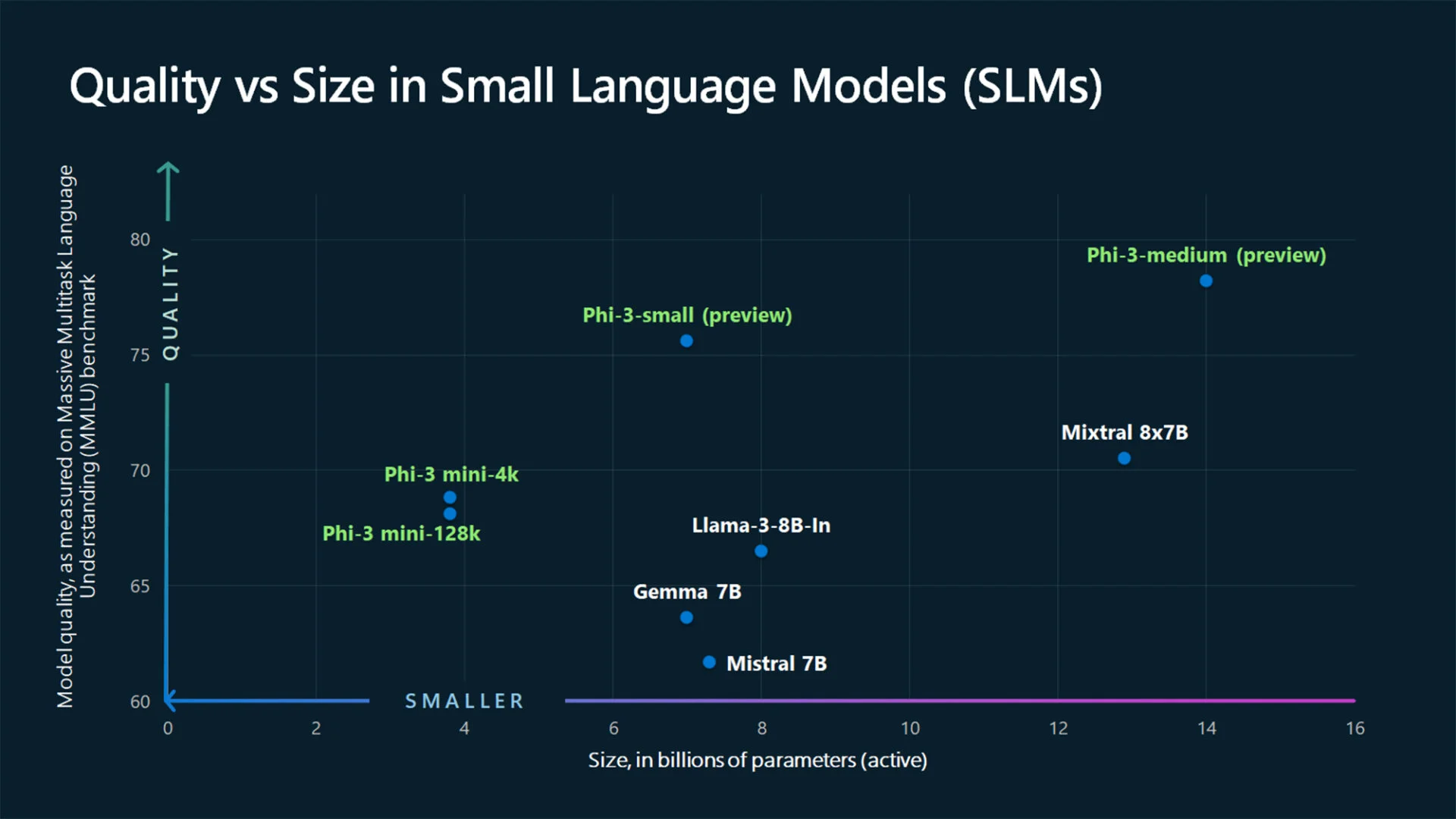
Phi-3 Mini 是第一個公開的三種子字串代表;另外兩個預計在未來幾個月推出,分別是 Phi-3 Small 和 Phi-3 Medium。從參數數量來看,這些模型分別需要 38 億、70 億和 140 億的土壤。此外,正如您對數字 3 所了解的那樣,已經有先例:Phi-1 和 Phi-2,後者於去年 12 月首次亮相。
儘管尺寸很小,Phi-3 Mini 的效率卻不低。微軟聲稱它提供的性能比兩倍大小的型號更好。在致我們同事的聲明中邊緣,微軟 Azure AI 平台副總裁 Eric Boyd 補充道“Phi-3 Mini 與 GPT-3.5 等 LLM 一樣高效,但格式更小”。
使用 LLM 培訓的 SLM
正如您可以想像的那樣,SLM 模型要想高效,就必須經過良好的訓練。雖然 LLM 是透過網路上收集的大量資料收集的,但對於 SML 來說,這種收集並不相關。因此,微軟團隊採用了不同的方法來訓練 Phi-3 Mini。「為什麼不搜尋非常高品質的數據,而不是對原始網路數據進行訓練? »微軟負責產生人工智慧研究的副總裁 Sébastien Bubeck 總結道。
然而,正如該公司指定的那樣,如果“區分高品質資訊和低品質資訊對人類來說並不困難”(一個有爭議的斷言),對於語言模型來說更是如此,除非另有證明,否則它只是一個沒有任何推理能力的數據吸塵器。也就是說,為了進行初步的整理以及相關資訊的選擇,微軟使用了LLM。據該公司介紹,一種新型訓練器解釋了 Phi-3 Mini 的卓越性能。
“當前一代大型語言模型的強大功能確實是我們以前在生成合成數據方面所沒有的工具”微軟研究院 AI 前沿實驗室主任 Ece Kamar 強調。基本上,我們找到了一些埃皮納勒大師和學生的形象,第一個將他的知識的一部分提煉到第二個。
事實上,小型人工智慧模型的運作成本比大型人工智慧模型更便宜,最重要的是,在當前的硬體狀態下,可以促進本地使用。
微軟解釋如下:該公司寫道,由於 SLM 能夠離線運行,更多的人將能夠以迄今為止不可能的方式使用人工智慧。如果在萬物互聯的時代,透過伺服器請求強大的聊天機器人似乎並不是不可逾越的障礙,那麼這實際上是來自一個生活在網路基礎設施相對發達的國家的城市居民的言論:雷德蒙德公司只是簡單地提到了這個案例缺乏蜂窩服務的農村地區;更具體地說,一個農民的例子,在檢查農作物並在葉子或樹枝上發現疾病跡象時,將能夠使用配備視覺能力的 SLM 拍攝相關農作物的照片,從而立即獲得有關以下問題的建議:如何治療寄生蟲或疾病-診斷和治療大概由拜耳直接決定,但這是另一個爭論。
微軟人工智慧副總裁 Luis Vargas 描繪了一個理想世界:「如果您所在的地區沒有良好的網絡,您仍然可以從設備上的人工智慧體驗中受益」;這要歸功於 SLM。喜樂啊!
來源 : 微軟