作為數百萬網路使用者使用的 ChatGPT 等對話代理的核心,語言模型解釋了人工智慧在自然語言處理 (NLP) 領域的相關性的演變。對這些語言模型(例如大語言模型(LLM))功能的簡短介紹將使我們能夠更好地得出定義。
人工智慧正經歷民主化浪潮空前的,感謝會話代理的到來,例如聊天GPT。它們使向公眾展示深度學習和人工智慧能力最引人注目的方面之一成為可能:透過演示如何挪用人類語言並與他們進行討論,而無需靠近盤子。
您肯定已經想知道,在如此短的時間內,我們如何從本質上透過程式碼與機器的關係轉變為這種簡單的自然語言,它只要求讓您想像與另一個人交談。這就是語言模型發揮作用的地方,雖然它仍然是一個使用向量和函數的電腦模型,但它充當了兩個似乎分離的實體(人類和機器)之間的緩衝區。
語言模型簡介
因此,語言模型是電腦系統,其使命是將自然語言翻譯給機器,讓機器理解、分析和回應請求,進行翻譯、總結,同時也模擬想像、反思,並考慮到什麼以前無法以功能的形式進行系統化與理論化:文化的細微差別、感受與情感。
自2017年以來,隨著法學碩士的興起,一場革命出現了(大語言模型),例如 Google 的 Transformers,它將文字理解和回應與自然語言的相關性推向了前所未有的水平。從現在開始,機器產生的數學模型與真正的人類智慧融合,吞下天文數字的數據,並建立對數十億參數的反應能力。
這些單字不再被一個接一個地分析或產生:機器能夠立即將一個陳述作為一個整體,並比任何人類更快地提供分析、總結、翻譯甚至更正和測試。
詞彙表
能夠進入語言模型的定義並很好為了能夠解釋會話代理如何運作,我們必須使用表達方式和特定詞彙。在開始之前,讓我們嘗試建立一個簡短的術語表。
聊天機器人:它通常被稱為“聊天機器人”,是一種允許您發送文字查詢並獲取回應的應用程式。聊天 GPT 和谷歌吟遊詩人是基於人工智慧和語言模型的對話代理。此前,聊天機器人在形式上可能受到更多限制,例如數位助理。
順序資料:所有句子、段落、文件都是順序資料的範例。在自然語言處理中,句子或其他文字單元中的單字順序對於理解整體意義至關重要。
入口和出口:條目通常是網路使用者發送的順序資料。輸出是機器考慮輸入和其他參數(例如先前的序列資料、透過訓練獲得的語言模型資料等)產生的序列資料。
設定:為了能夠理解、分析並提出對輸入的回應,語言模型使用一整套參數,這些參數是透過訓練人工智慧獲得的。這些參數稱為權重,根據資料庫中的範例進行調整。參數越多,語言模型就越能夠分析輸入並提供更複雜的輸出。
NLP(自然語言處理):自然語言處理學科的所有專業領域。這可能涉及翻譯、摘要、生成甚至文本分類。 ChatGPT 等工具將所有這些元素結合在一起。

定義人工智慧語言模型
ChatGPT 或 Bard 型對話代理背後的語言模型是一個允許機器理解並產生自然語言文本的系統,即人類的自然語言。為了能夠用一種語言說話、理解上下文、感受語氣和其他微妙之處、文化方面、學習模式並提出相關響應,語言模型必須依賴大量數據並知道如何處理和正確應用它它與用戶輸入。
一些有限的語言模型適用於純統計模型,而其他語言模型(例如法學碩士)則適用於機器學習。最先進的語言模型都能夠分析所有單字和單字組之間的關係、上下文,並將先前的文字序列保留在記憶體中以考慮時間上下文。它依賴於更多參數並引入了其他技術,例如“令牌”和“掩碼”。
語言模型是會話代理的計算核心:當使用者的文字輸入轉換為一系列數字(稱為向量)時,它們就會發揮作用,並透過多種類型的資料編碼器、解碼器以及演化而來的方法進行分析。當機器產生文字輸出並顯示在網路使用者的螢幕上時,它的作用就結束了。
載體的作用
在所有情況下,這些模型都是預測單字或單字序列出現在句子中的機率的數學模型。因此,這些模型會經過真正的電腦處理——這並不神奇。它們使用演算法模型進行翻譯,因此涉及系統將輸入轉換為數字,然後再將其轉換回文字以進行輸出。
同時,它們變成了稱為向量的數字序列。在 NLP 中,這些向量可以相對於其他單字進行分類,從而建立它們之間的鄰近度分數。向量中的位數決定了模型的維度。這些向量對於定義每個單字的含義、使自然語言數學化並最終使其能夠模仿人類理解及其語言至關重要。
隨著時間的推移,向量也開始被用來考慮自然語言中更微妙的點:例如影射、情感、幽默。
人工智慧的作用
語言模型是自然語言處理 (NLP) 人工智慧領域的核心元素。那什麼是人工智慧的作用?為了能夠建立高品質的語言模型,必須考慮大量數據,即使只是為了建立單字之間的分類、它們的相似性、它們的差異等。為此,神經網路可以毫不費力地在創紀錄的時間內完成人類所能完成的艱鉅工作。
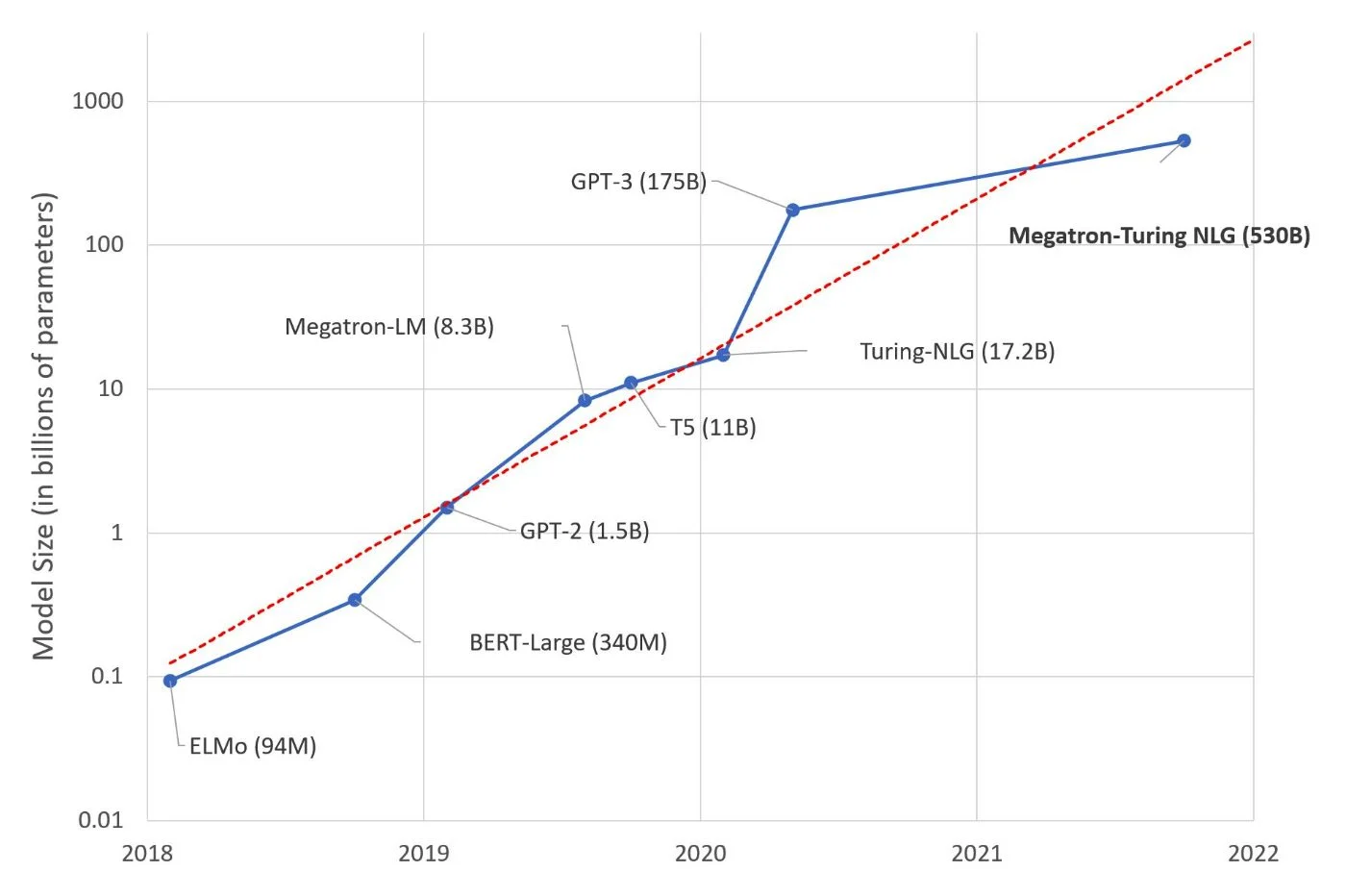
因此,人工智慧在語言模型中的地位尤其體現在來自大量文字資料的訓練中——通常法學碩士是在一組超過100,000 億個單字(10B) 上進行預訓練的,特別是來自Common Crawl、The Pile、MassiveText、維基百科的單字和 GitHub。但人工智慧隨後也會出現,以幫助模型提供上下文和智慧響應的能力,特別是透過繼續學習。
如今,隨著機器學習甚至深度學習的到來,語言模型的能力也取得了進展。語言模型達到Meta 的 Llama 2 上的 70 B 設置OpenAI 的 GPT-3 上有 1750 億美元。公眾已知(和使用)的主要是大語言模型(法學碩士),但要達到我們今天所知道的,這些模型依賴其他更有限的模型,但每個模型都將自己的一部分融入法學碩士的設計中。
循環網路的作用
在形成我們今天所知的法學碩士模型之前,語言模型首先是基於循環網路的概念。這些模型以數字方式處理文字數據,並用思維向量分析每個單字的每個向量。思想向量遵循相同的原則,因此在句子中添加每個新單字後都會對其進行調整。就像人腦在閱讀過程中逐字發現句子的含義,並透過連續閱讀的每個單字形成句子的想法一樣,循環網絡因此可以有很好的理解,並提供更相關和更相關的信息。這個向量,上下文中的輸出。
變形金剛的角色
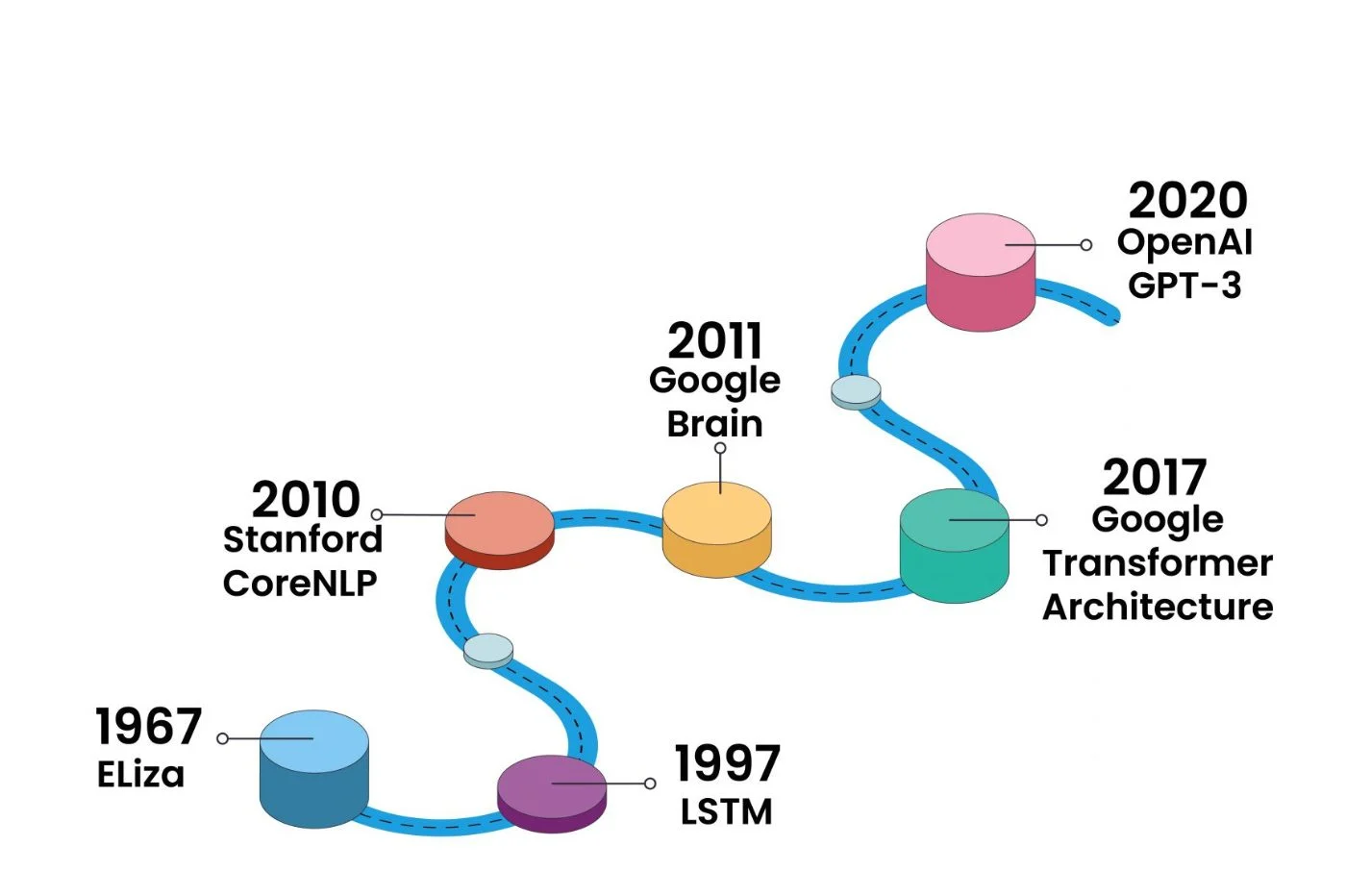
大型語言模型 (LLM) 並非一蹴可幾。在它們和循環網路之間有幾個改進的版本,試圖糾正模型理解中的缺陷,特別是由於記憶體限制和單字重要性的權重。我們特別可以引用長短期記憶(LSTM)和門控循環單元(GRU)。但語言模型真正的革命要追溯到2017年,Google研究人員提出的Transformers模型,導致了LLM最受歡迎原理的出現。
Transformer 的方法與循環網路不同:它不是分析每個單詞,而是分析整個句子或一組句子。然後,連結到單字的每個向量的權重通過標記和掩碼的原則。 Transformer 是一種允許以新方式對上下文資料和文字資料進行建模的架構。足以消除記憶問題、句子中單字的位置問題、建立單字的非本地關係的問題。
「面具」有兩種類型:因果過濾器,根據句子的上下文影響一個向量而不是另一個向量,以及填充過濾器,它對理解或響應沒有影響,但只允許不同長度的句子。標準化為相同大小的句子(我們仍然在數學上,一切都必須是正方形的)……這些單字沒有用,也不應該被機器考慮在內。
就令牌而言,它們透過添加更多需要考慮的事項以及理解每個單字的雙向維度來豐富循環網路的向量。例如,特徵標記(稱為「嵌入」)被添加到注意力層中,對句子中每個單字的重要性進行加權,並在每個單字之間建立鏈接,而不會使整體含義變得更加複雜。不同的語言模型繼續優化這些標記及其處理。
谷歌首先推出了 BERT,此後推出了 LaMDA(也稱為 Lambda),最後推出了 PaLM(用於廣義語言理解和多個資訊來源的整合)。 OpenAI 也基於 GPT-3、GPT-3.5 和 GPT-4 的 Transformer 模型。其語言模型的第一個版本可以追溯到 2018 年。GPT-4它以更多的輸入(不僅限於文字輸入,還接受圖像或音訊)而脫穎而出,並且參數將遠大於 GPT-3 的 1750 億權重。
語言模型的局限性
我們必須區分兩件事:語言模型的限制和一般語言模型的限制。質疑一種語言模式不同於質疑整個語言模式的演化能力。
然而,在使用自然語言與機器互動時,是否存在完全不同的解決方案?到目前為止,所有語言模型都有其局限性,但任何改進途徑仍然涉及相同的語言模型整體原理和演算法豐富……與人類靈魂和意識相去甚遠。
因此,語言模型的原理仍然特別依賴能夠存取重要但並非無限的數據的高品質培訓(由於缺乏必要的電腦資源)。同時,嚴格來說,語言模型什麼都不知道。他們只會做類比,不會記憶。因此,發明的反應占主導地位,與「幻覺」相比更常見。
最終,透過查看語言模型來理解對話代理類似於打開資料中心的大門來了解互聯網的功能(和限制)。 ChatGPT 今天提供的魔力是可以解釋的,其工作成果將回到由人類想像和實施的成品系統中。
在 Meta,人工智慧的發展部分是法國故事。在與 Jérome Pesenti 合作數年之後,研究員Yann LeCun 巡迴演出獎得主去年六月討論了一種新的語言模型的主題,稱為傑帕(「聯合嵌入預測架構」),其重大進步是“機器至少和人類一樣聰明,甚至更聰明”Facebook 母公司人工智慧科學研究負責人解釋。透過 JEPA,語言模型架構將考慮新的因素“了解底層世界”。
「如今,與人類的能力相比,機器學習確實很糟糕。 [……]因此,我們缺少了一些巨大的東西”,Yann LeCun 補充道,他毫不諱言,還宣稱「今天的人工智慧和機器學習真的很糟糕。人類有常識,但機器沒有。對他來說,關注的途徑首先是認知面,也就是人腦的功能。語言模型過於關注語言的簡單理論化和單字的權重。
結論:魔術何時真正超越我們
多虧了語言模型,人工智慧已經學會如何說話。從 n 元模型到大型語言模型(法學碩士),它是對話代理的核心,最終是網路使用者在去年年底發布的 ChatGPT 中發現的真正驚喜。雖然Google、Meta、OpenAI 和許多其他公司正在完善自己的技術,但如今它們都依賴語言模型系統邏輯,能夠將人類與機器連接起來,形成兩個人之間幾乎完美的對話幻覺。
然而,在討論中,我們更願意將效果連結起來哇廣義的人工智慧,而不引用和解釋其創建者完全了解的將自然語言轉錄成數字序列、「標記」向量的系統的功能, 的與認知學習無關的輸入和輸出的「面具」。但批評已經足夠多了,語言模型目前仍然是唯一為 NLP 領域的對話代理和其他工具提供實現其雄心的手段的模型。
認知邏輯與量子計算機
因此,我們模仿演繹、分析、反思……但是對話代理提出的結果,儘管他們是在虛張聲勢,但他們的魔術的秘密在某種程度上還是顯而易見的。因此,未來語言模型必須繼續擴大規模和運作能力。在不久的將來,最大的改進途徑將是透過硬體:量子電腦的到來將使語言模型和人工智慧進一步超越當前的規模。
到目前為止,所有模型都不相同,當我們面臨極限時,有些模型會回歸邏輯基礎:專注於單一目標,而忽略全局人工智慧——擁有一切問題答案的對話代理。許多公司會發現專注於某個領域更有趣,尤其是研究(例如醫學和生物學研究)以及在開源模型上共同分享想法和進步的社群已經在人工智慧世界眾所周知的平台上聚會:抱臉。
我們需要關注的是語言模型的明顯限制。質疑它的存在就是質疑 NLP 至今運作的核心。從那裡開始,新的系統可能會誕生並包含一個更大的系統,這次將尋求模擬和模仿人類特有的認知。從那時起,魔術將變得更大——幻象將不再是戴帽子的兔子,而是魔術師本人。
無論如何,我們會永遠堅持魔法嗎?