在30岁时遭受脑干中风的近二十年后,美国的一名妇女重新获得了实时的想法,这要归功于新的脑部计算机界面(BCI)过程。
通过以80毫秒的增量分析她的大脑活动,并将其转化为她声音的合成版本,美国研究人员的创新方法消除了令人沮丧的延迟,困扰着该技术的先前版本。
我们身体传达声音的能力,因为我们认为它们是我们经常认为的功能。只有在极少数时刻,当我们被迫为翻译者停下来,或者听到我们的演讲被演讲者延迟时,我们是否会欣赏自己的解剖学的速度。
对于那些塑造声音能力已从他们的人那里切断的人大脑的语音中心,无论是否通过诸如或者关键病变 ,结合专业软件的大脑植入物已承诺将获得新的生活租赁。
的已经看到了最近,每个人都旨在在思想中发表演讲时缩短。
大多数现有方法都需要在软件破译其含义之前要考虑一部分文本,这可以大大拖出语音启动和发声之间的几秒钟。
这种不自然的不仅是那些不自然的,对于使用该系统的人来说,它也会令人沮丧和不舒服。
加州大学伯克利分校和旧金山的研究人员“改善语音综合延迟和解码速度对于动态对话和流利的交流至关重要。”在他们已发布的报告中写。
这是“语音综合需要额外的时间进行播放的事实以及用户和听众理解合成音频的事实,这使得这变得更加复杂,”解释该团队由加州大学伯克利计算机工程师Kaylo Littlejohn领导。
更重要的是,大多数现有的方法都依赖于“扬声器”来训练界面,从而通过发声的动作来训练界面。对于那些无法实践的人,或者总是很难说话,向他们的解码软件提供足够的数据可能是一个挑战。
为了克服这两个障碍,研究人员在47岁参与者的感觉运动皮层活动上训练了一个灵活,深度学习的神经网络,而她从刚刚超过1000个单词的词汇中默默地“讲”了100个独特的句子。
Littlejohn及其同事还使用较小的单词基于50个短语使用了辅助形式的通信形式。
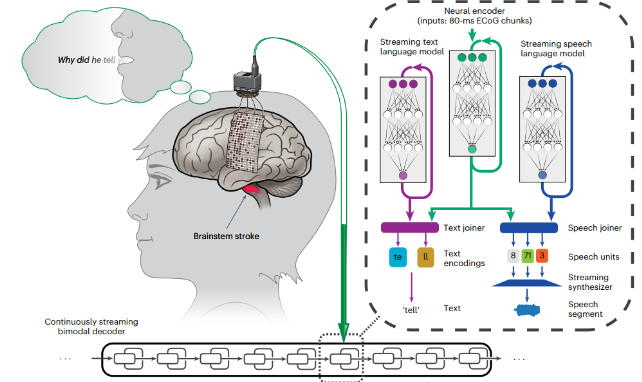
与以前的方法不同,此过程不涉及试图发声的参与者,而只是想出她的脑海中的句子。
该系统对两种通信方法的解码都很重要,每分钟平均单词的平均数量接近了以前方法的两倍。
重要的是,使用一种预测方法可以持续地触发地解释,使参与者的语音以比其他方法快8倍的自然方式流动。得益于基于她的演讲的先前录音,这甚至听起来像是她自己的声音。
团队表明他们的策略甚至可以解释代表未经故意训练的单词的神经信号,因此脱机过程中没有限制。
作者指出,在该方法可以被视为临床上可行之前,还有很大的改进空间。尽管演讲是可理解的,但它远远没有解码文本的方法。
考虑 来了但是,有理由乐观地,那些没有声音的人很快就会唱着研究人员及其思维方式的赞美。
这项研究发表在自然神经科学。