
就像您可能求助于Twitter或Facebook有关周围发生的事情的脉动一样,参与传染病计算建模项目的研究人员正在转向匿名社交媒体和其他公开可用的Web数据,以提高其预测爆发爆发的能力,并开发可以帮助卫生官员回应的工具。
采矿Wikipedia数据
“在传染病的预测方面,要领先曲线是有问题的,因为来自官方公共卫生来源的数据是回顾性的,”美国国立卫生研究院的艾琳·埃克斯特兰德(Irene Eckstrand传染病药物研究模型(MIDAS)。 “将来自社交媒体和其他Web来源的实时匿名数据纳入疾病建模工具可能会有所帮助,但这也带来了挑战。”
为了评估网络改善传染病预测工作的潜力,MIDAS研究员洛斯阿拉莫斯国家实验室的Sara del Valle进行了概念验证实验,涉及Wikipedia每小时向任何感兴趣的政党发行的数据。 Del Valle的研究小组根据七种语言的疾病相关维基百科页面的页面查看历史建立了模型。科学家对其其他模型进行了测试,这些模型依赖于使用这些语言报告的国家 /地区报告的官方健康数据。通过比较不同的建模方法的结果,洛斯阿拉莫斯团队得出结论,基于Wikipedia的流感和登革热的建模结果比其他疾病的建模结果更好。
“我们能够使用Wikipedia来预测最多4周内生病的人数,” Del Valle解释说。类似研究的结果这证实了这种预测季节性流感蔓延的方法的潜力。
Del Valle指出,Wikipedia预测方法确实有一些局限性。例如,在某些疾病是地方性疾病的国家中,互联网使用率低可能有助于解释为什么她小组的霍乱模型的表现不如流感和登革热。
开发应用程序
Eckstrand说:“研究如何适当有效地使用社交媒体和相关信息进行传染病预测也很重要。”
为此,由弗吉尼亚理工大学的Stephen Eubank领导的MIDAS集团一直与弗吉尼亚卫生部的一名地区流行病学家合作,以测试并有可能扩大名为Epidash的计划的应用。
Epidash是一个使用机器学习算法来筛选与流感,诺如病毒甚至莱姆病有关的关键字的匿名公开推文的平台。监视关于主题的推文的兴起和下降可以帮助努力识别和应对新兴疾病趋势。
像德尔·瓦莱(Del Valle)一样,Eubank在使用社交媒体进行疾病监测和预测工作时指出了各种特殊考虑。这些包括技术障碍,例如纳入快速更改的主题标签或流行语以及隐私问题。他的小组最近发表了一篇文章,该文章提出了使用Twitter数据进行研究的道德标准。
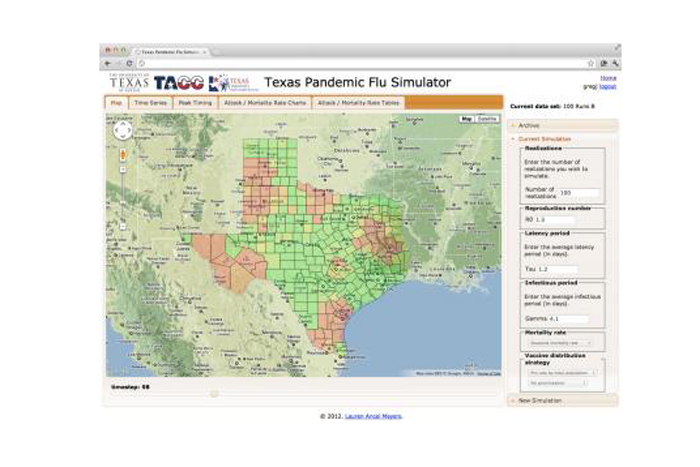
数字数据帮助德克萨斯大学奥斯汀分校的MIDAS调查员Lauren Ancel Meyers建立了一个名为Texas的流感监测系统大流行Flu Toolkit是德克萨斯州卫生官员可以用来评估不同干预措施(例如抗病毒药,疫苗和学校关闭)的潜在有效性的一套在线工具。
MIDAS研究人员同意,将新颖的信息来源(例如公开可用的Web数据)整合到计算建模工具中可以彻底改变疾病监测和预测。正如迈耶斯(Meyers)所说:“我们正处于冰山一角。”
本文报道的研究部分由NIH在赠款下资助U01GM097658,,,,U01GM070694和U01GM087719。
这篇内在的生活科学文章是由与生活协会合作的国家一般医学科学研究所,一部分国立卫生研究院。








