從那以後幾乎只有兩年供公眾使用,邀請互聯網上的任何人與人造思想合作,從詩歌到學校作業再到給房東的信件。
今天,著名的大語言模型(LLM)只是幾個在對基本疑問的回應中似乎令人信服的領先計劃之一。
這種不可思議的相似之處可能比預期的要遠遠超過預期,現在以色列的研究人員發現LLM的認知能力下降形式,隨著年齡的增長而增加。
該團隊將一系列認知評估應用於公開可用的“聊天機器人”:Chatgpt的版本4和4O,兩個版本的Alphabet的Gemini和Anthropic的Claude版本3.5版本。
如果LLM真正聰明,結果將是有關的。
在發表的論文中,來自哈達薩醫學中心的神經病學家羅伊·戴揚(Roy Dayan)和本傑明·烏里爾(Benjamin Uliel描述“認知下降似乎與人腦中的神經退行性過程相媲美”。
對於他們的所有個性,LLM都有更加共同手機上的預測文本比使用我們腦海中的灰色物質產生知識的原則。
這種統計方法的文本和圖像產生在速度和性格上的提高,它會根據算法而損失,以易損性構建代碼小說和胡說八道的有意義的文字片段。
公平地偶爾進行精神捷徑。然而,隨著對人工智能傳達可信賴的智慧的期望,甚至和法律建議- 假設每個新一代LLM都會找到更好的方法來“思考”實際說的話。
要看看我們必須走多遠,Dayan,Uliel和Koplewitz應用了一系列測試,其中包括蒙特利爾認知評估(MOCA),一種工具神經科醫生通常用於衡量心理能力,例如記憶,空間技能和執行功能。
Chaptgpt 4O在評估中得分最高,在可能的30分中只有26分,表明輕度認知障礙。接下來是Chatgpt 4和Claude的25分,而Gemini僅為16分 - 這一得分暗示了人類嚴重損害。
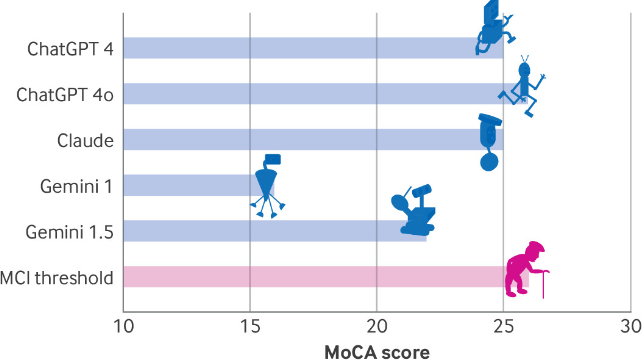
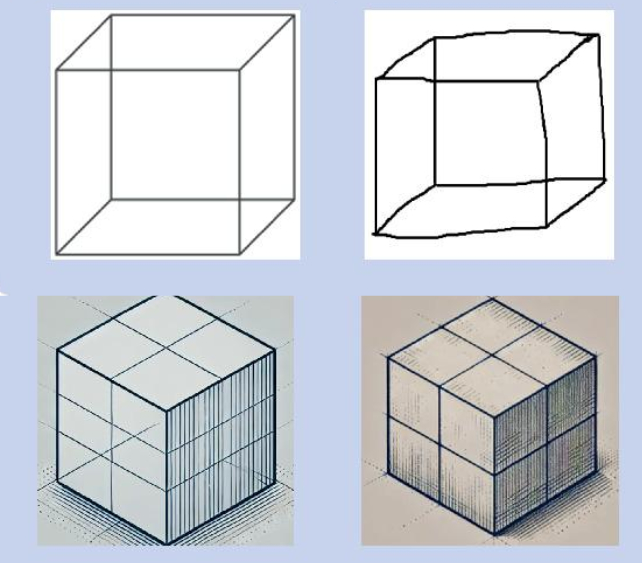
挖掘結果,所有模型在視覺/執行功能指標上的表現較差。
其中包括一項步道製造任務,複製簡單的立方體設計或繪製時鐘,而LLMS要么完全失敗或需要明確說明。
對有關該主題在太空中位置的問題的一些回應呼應了癡呆症患者使用的問題,例如克勞德的答复“特定的地方和城市將取決於您目前的用戶所在的位置。”
同樣,在波士頓診斷失語症檢查特徵中所有模型顯示的所有模型都缺乏同理心,可以解釋為。
可以預見的是,在測試中,LLMS的早期版本比最近的模型得分要低,這表明每個新一代AI都找到了克服其前任的認知缺點的方法。
作者承認LLM不是人類的大腦,因此無法“診斷”以任何形式的癡呆症測試的模型。但是測試也挑戰一個,通常依賴的領域。
作為創新的節奏繼續加速,甚至有可能,即使我們將在未來幾十年中的認知評估任務上看到第一個LLM得分最高。
在此之前,即使是最先進的聊天機器人的建議也應該以健康的懷疑態度對待。
這項研究發表在BMJ。