當我們說話時,我們的大腦會編排口腔和喉嚨肌肉的複雜舞蹈,以形成組成單字的聲音。 這種複雜的表現反映在發送到言語肌肉的電訊號中。
在一項新的突破中,科學家現在將大量微型感測器塞進一個不比郵票大的空間中,以讀取這種複雜的電信號組合,從而預測一個人試圖發出的聲音。
「言語義肢」打開了通往未來的大門,因為神經系統疾病而無法說話的人們可以透過思想進行交流。
你的第一個反應可能是假設它會讀心。 更準確的是,感應器可偵測我們想要移動嘴唇、舌頭、下巴和喉部的哪些肌肉。
“許多患者患有使人衰弱的運動障礙,例如 ALS(肌萎縮側索硬化症)或閉鎖綜合症,這會損害他們的說話能力,”說共同資深作者、杜克大學神經科學家格雷戈里·科根。
“但目前允許他們進行通信的工具通常非常緩慢且繁瑣。”
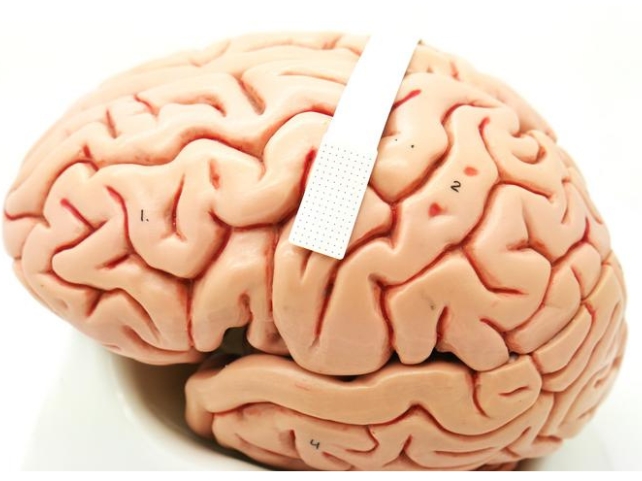
類似的最新技術以大約平均語速一半的速度解碼語音。 團隊認為他們的技術應該可以改善延遲,因為它可以在一個微小的陣列上安裝更多的電極來記錄更精確的訊號,儘管在向公眾提供語音義肢之前還需要完成一些工作。
共同資深作者、杜克大學生物醫學工程師喬納森·維文蒂 (Jonathan Viventi) 表示:“我們現在的速度仍然比自然語音慢得多,但你可以看到可能達到目標的軌跡。”九月說。
研究人員在醫用級超薄柔性塑膠上建構了電極陣列,電極間距不到兩毫米,即使來自非常靠近的神經元也可以檢測到特定訊號。

為了測試這些微型大腦錄音對於語音解碼的有用性,他們暫時將裝置植入四名沒有言語障礙的患者體內。
抓住患者接受手術的機會——其中三名患者因運動障礙,另一名患者因腫瘤切除——他們必須盡快完成手術。
「我喜歡將其與 NASCAR 維修站工作人員進行比較,」科根說。 「我們不想為操作程序增加任何額外的時間,所以我們必須在 15 分鐘內進出。
“一旦外科醫生和醫療團隊說‘走!’ 我們立即採取行動,患者完成了任務。
當植入微型陣列時,研究小組能夠記錄大腦言語運動皮質的活動,當患者重複 52 個無意義的單字時,這些活動會向言語肌肉發出訊號。 「非詞語」包括九個不同的詞音素,創建口語單字的最小聲音單位。
錄音顯示音素引發了不同的訊號發射模式,他們注意到這些發射模式偶爾會相互重疊,有點像管弦樂團中音樂家混合音符的方式。 這表明我們的大腦在發出聲音時即時動態地調整我們的言語。
杜克大學生物醫學工程師 Suseendrakumar Duraivel 使用了一種機器學習演算法評估記錄的訊息,以確定大腦活動如何預測未來的言語。
有些聲音的預測準確率高達 84%,特別是如果該聲音是非單字的開頭,例如 gak 中的「g」。 在更複雜的情況下,例如非單字中間和末尾的音素,準確率會有所不同並下降,總體而言,解碼器的平均準確率為 40%。
這是基於每個參與者僅 90 秒的數據樣本,考慮到現有技術需要數小時的數據進行解碼,這令人印象深刻。
美國國立衛生研究院的巨額資助已被獎勵作為這一充滿希望的開始的結果,支持進一步的研究和微調技術。
“我們現在正在開發相同類型的錄音設備,但沒有任何電線,”說科根。 “你可以四處走動,而不必綁在電源插座上,這真的很令人興奮。”
該研究發表於自然通訊。